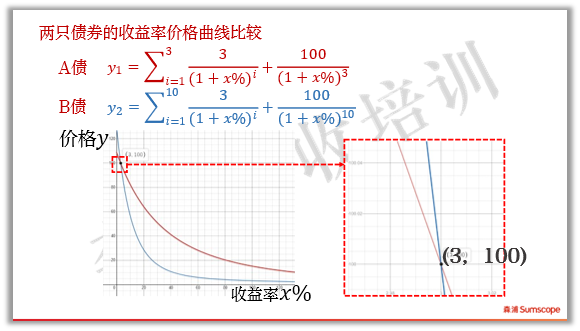
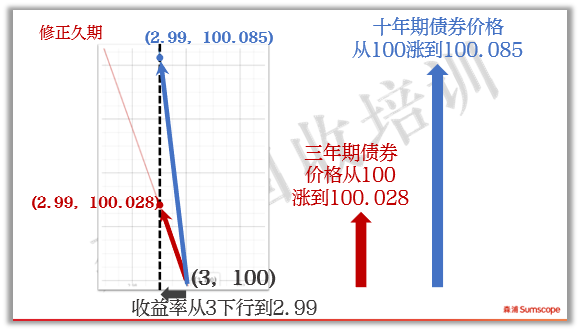
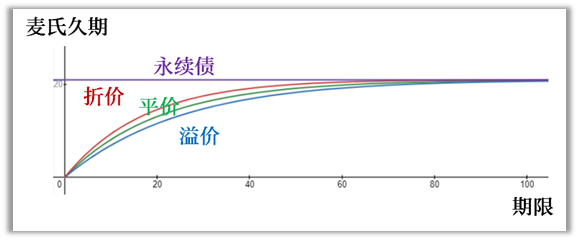
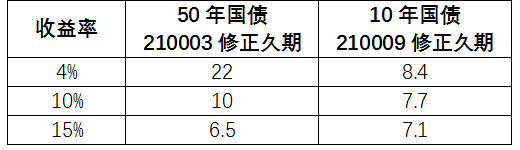
1、关于模型
同一家管理人,其策略体系如果覆盖了指数增强、全市场选股、市场中性、灵活对冲、股票多空等,那么在选股端的模型是相同的,不存在不同策略使用不同模型。
在相同的策略框架下,做一些局部的调整就能构建出上述不同的策略。
核心模型是选股,传统的方法是对模型输入因子,输出股票组合;另一种端到端(神经网络)模型,输入的是数据,输出股票组合。
无论是哪种方式,具体的输出首先是一张打分表,将全市场的股票按照分数由高到低排列。
如果策略是指数增强,接下去就要按照对标的基准指数在行业和Barra风格上进行约束。
什么叫做约束?也就是将模型输出的组合,按照基准指数做调整,将每一个细项(风格、行业)的偏离(超过或者低于基准指数中的权重)控制在某个限度之内。
这个限度如何衡量?使用标准差SD,单项偏低超过0.5个SD之内的,叫做约束严格(最后的总偏离是单项偏离的加权平均)。控制在0.5~1个SD之间的也算是正常。如果在某一项,或者某几项的偏离很大,我胡乱举个例子在小市值上直接偏离100个SD,这就叫做暴露(小市值上)。
简单记忆:指数增强 = 量化选股 + 风格&行业约束
如果不想做约束可不可以?
可以。这样就完全按照模型选出来的股票去买。这个策略就叫做全市场选股。因为不对任何基准指数所包含的行业和风格进行约束,又叫做空气指增(对着空气约束 = 不约束)。
空气指增 = 量化选股 + 0约束
如果考虑到指数下跌,想要把beta下行的风险对冲掉。
这时可以选择两种方式:
第一种,通过做空股指期货(IF、IC、IM),这就是市场中性。
市场中性 = 量化选股 + 风格&行业约束 + 空股指期货,即指增附加一个股指期货的多头端。
在股指期货的选择和权重上还需要跟指增所对应的基准指数风格对应,但都会留出一部分风格上的暴露。
第二种,通过融券做空个股,这就是最近比较火的股票多空。
股票多空 = 量化选股 + 融券做空
这里是不需要去对照任何一个基准指数的风格的,而是需要根据空头端去匹配多头端。
2、为什么根据空头匹配多头?
目前看下来市场上主流的几家管理人的多空策略都是由空头端匹配多头端。
为什么?
因为空头融券是有稀缺性的,稀缺意味着在可得性上存在不确定性。
比如模型这批输出的排名几只AI票排在后列,但是对不起,融不到这几只个券,只能给你一些汽车的空头券。这时候你只能去调整多头端的建仓来匹配可得的空头券。
多头端一般不会出现买不到的情况。所以,从操作层面大部分是先确定空头端,然后根据空头来构建多头。
3、关于融券
融券分为场内和场外。
场内是主要方式,但限制比较多。
随借随还是一种业务话术,比如你借7天,可能才用了3天就要决定是否要续借。再比如卖出只能挂卖二,不能市价做空(卖一),这样就可能错过一些盘中的机会。
实际操作中这样的细节问题还有很多,这不是券商之间的优劣,而是场内融券机制如此。可以理解成现在没有高速公路,只有临时的水泥路。
场外券起步比场内晚,目前整个量比较小,但相比场内操作上更加灵活。
约券的顺序:融券T > 股票多空 > 实时券池
多空策略要看下单是T+1,还是盘中下单?前者先约券,后者使用的是实时券池。
实时券池x = X券商总券池 – 融券T约券总量 – 多空策略约券总量 – 其他空头约券总量
4、场内融券限制后的变化
新规前100%做多空策略,新规主要对场内融券规则做了限制。
如果管理人的策略是只做场内多空,那就大致就阉割为:
60%多空(场内)+40%的中性。
如果使用场外融券,可以增加一些券源,也就是空头机会,策略结构变为:
70~75%多空+25~30%的中性。
结果就是收益降低,多空策略收益>中性策略的收益。回撤是否降低,我没法确定,因为我见过中性策略回撤七八个点甚至超过10个点的,所以无法断言说中性策略的回撤就一定比多空小。
5、收益、风险来源
多空策略的收益就是来源于选股alpha,一揽子个股因强弱不同的差异加总。其次,为了实现这个alpha需要有充足券源的保证,这是执行部分。
因此多空策略既考验量化管理人的alpha能力,也考验期资源和商务能力,以及运营水平。
收益来源对应的便是风险来源,主要有:
第一,alpha端的回撤。
比如输出的打分表出现了错误,做多的强势股在实际行情中走弱,做空的弱势股在实际行情中走强,这时候就会出现回撤,而这个风险归因于alpha端的风险,属于策略层面。
第二,券源层面的风险。
券的可得性风险,直接影响该策略是否能够跑起来。
常用的指标是匹配度和到券率。匹配度是根据模型输出的空头券与合作券商能够提供给这家管理人的券源的占比,如果这个数字很低,意味着该券商的券源无法满足其策略要求。到券率是实际操作时你能够拿到的券,有时候在业务开始前你拿到的excel清单中会有许多券,而实际操作时你真正能够得到券会有差异,这当中存在一些风险。
比如模型输出要500个空头券,X券商说我只有50只券可以给你。你想50只比没有好吧,于是就做了50只空头,并对此匹配50只多头。但对不起,这50只空头券当中有30只是庄股,人家用call建的多头。你的空头端就会崩掉(不停被拉涨停~),这件事情在早年发生过。
另一个风险是召回(Recall),简单说就是你的空头端没了,这样多头就裸露了出来。有些召回是T+1日,有些是实时召回,全部是操作上的细节,这里就不展开了。
召回比例比较低的时候,双方只要及时沟通影响是不大的。比较麻烦的是突然之间出现一个很大比例的召回,这时候就是考验管理人商务和应急的能力了。
由于空头券源差异,导致多头端也不一样,整个多空持仓组合有差异。这就意味着,同一个管理人在不同券商做场内融券多空的业绩在局部时间点上会不一样。
此外,如果同一个券商,同一个多空策略不同多空产品的净值出现差异,那就要去了解是否在下单环节出现了优先顺序?
6、股票多空策略的业务模式
场内融券,一支基金产品只能开一个两融账户。
因此,大部分多空管理人会选择在主流的券源机构开设一只旗舰产品。
考虑到场内的融券效率比较低,包括券源可能比较有限,这时候就需要做一个选择:是否通过开设场外融券来补充券源?
场外融券是通过SAC进行的,一支基金产品可以签多个SAC,即可以接入多家场外券源。
实操中要注意的事项是资金分配划账,多头端和空头端是一起走,不可以在A券商建多头,在B券商场外融券做空。只能在A券商的做一部分多头+场内融券空,在B券商做一部分多头+场外融券空。这时候就涉及到放多少资金到B券商账户上的问题,这又是操作层面的细节了。
另外,选择使用场外券有一个弊端:
大部分券商的合规对场外融券产品有所排斥,这就意味着如果你做的是场外场内融券多空,该券商的自营、资管就无法下投,也没办法上代销。
如今有些管理人的多空策略上了某些券商的代销,基本上是只做场内融券多空。
当然,如果资金来源不依赖券商机构和代销,那么就可以忽略这一点了。
7、境内多空管理人的分类
融券分场内、场外;交易频段分低频和高频。
比如场内低频融券多空,场内场外高频融券多空。
大家可以通过这些分类,把策略看得细一些。
8、境外融券多空
国内量化私募在境外做融券多空的数量比较少,原因还是卡在券源上。
这个时间壁垒大致是3年,假设你找到了正确的方式,找到了正确的人,商务能力可以,大约3年把策略搞成熟。
9、真多空、假多空
可以预见接下来这个策略会被许多家管理人去尝试,甚至“抄袭”。毕竟什么热大家就追什么是咱们财富行业的一个特点。
但是多空这个策略,除了在多头和空头两端市值对齐(相等),还要尽可能将多空两头在风格、行业上的暴露给控制住。
假多空通常指粗放地在做多做空金额上对齐,其他都不对齐。比如今年上半年小市值跑得好,500指数比较弱一些。那么就多头端买一揽子小市值甚至微盘股,空头端做空一堆500成分股和大票。
这个做法在上周五就会出事,因为500成分股表现远远好于微盘股、上证50,于是形成多空双杀,回撤就会很厉害,甚至超过指数增强。
所以大家不要因为策略有稀缺性就盲目追逐,最好先了解下对方是怎么做的比较好。
10、多空策略面向哪些资金?
自有资金,直投资金比较多,代销端的钱比较少。
目前财富端零星出现了多空策略的代销,这块趋势后续还需要观察。