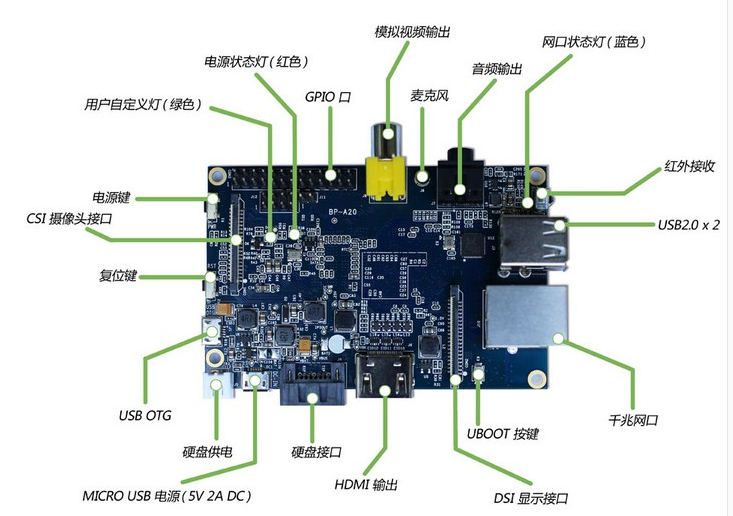
最近对于BananaPi系列的开发板比较感兴趣,于是在网上淘宝淘到一个BananaPi开发板,我使用的是BananaPi V1版本,目前官方已经开发出BananaPi Pro版本,自带无线模块。大家可以看一下http://www.lemaker.org/。
具体硬件参数,基本与pro相同。
下面开始烧录OpenWrt的系统。由于我对内核比较熟悉,我直接是从仓库构建的openwrt。如果对于openwrt不熟悉的话,可以从http://downloads.openwrt.org/下载对应的版本,但是需要注意的是由于openwrt属于嵌入式系统,要想让系统在板子上运行起来,我们需要下载对应的版本的img。
如果你的硬件不在http://downloads.openwrt.org/barrier_breaker/14.07/这个列表中,又有些技术基础的话,最好从仓库clone,自己构建,可以省很多时间!
因为官方默认的镜像,不带usb-mod,也就是不支持usb转Ethernet接口,这个在我初期构建的时候麻烦很大!
git 仓库地址:https://github.com/openwrt-mirror/openwrt
将仓库pull下来之后,我们可以从linux的仓库中通过apt-get/yum方式安装下载最新的交叉编译环境包。下面的图是apt的,关于yum的,可以使用yum search进行查找,名字应该差不多。
sudo apt-get install gcc sudo apt-get install g++ sudo apt-get install binutils sudo apt-get install patch sudo apt-get install bzip2 sudo apt-get install flex sudo apt-get install bison sudo apt-get install make sudo apt-get install autoconf sudo apt-get install gettext sudo apt-get install texinfo sudo apt-get install unzip sudo apt-get install sharutils sudo apt-get install subversion sudo apt-get install libncurses5-dev sudo apt-get install ncurses-term sudo apt-get install zlib1g-dev sudo apt-get install gawk sudo apt-get install asciidoc sudo apt-get install libz-dev
我们可以像平时编译内核那种方式,通过make menuconfig方式,裁剪内核,最主要的是进入这个界面,我们要指定构建内核的芯片,和构建目标。也就是Target system和Target Profile ,Target Images我们选择ext4系统与GZip Images就足够了。
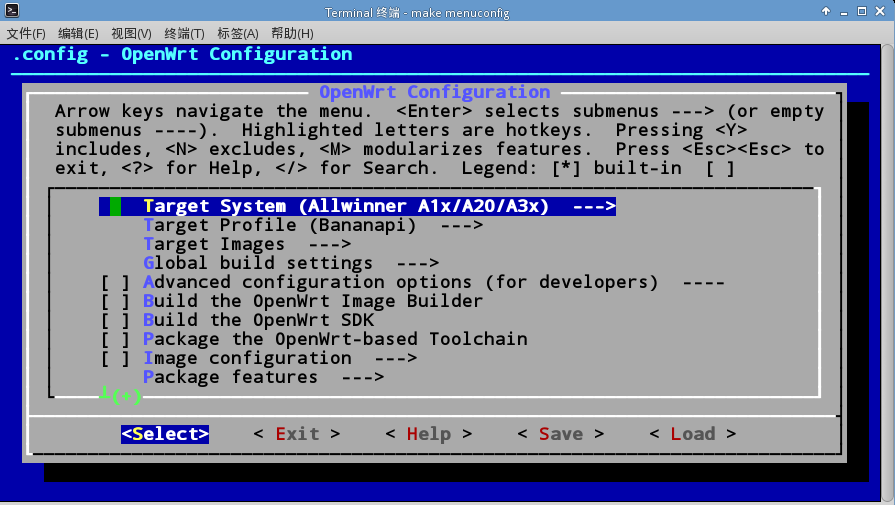
然后在下面的Iuci中选择需要构建的包,因为Openwrt管理界面是网页形式,所以要选择一个http服务器,我们默认自选uhttpd即可,如果又选了其他的服务器,可能存在登陆错误的现象!如果你需要Usb一系列设备,就需要在Kernel Modules中编译相关模块。
最后保存设置,使用make V=99开始编译,第一次编译需要下载很多外部库,总的时间3h左右,如果不清理的话,下次编译时间会大大缩短。
———————-
现在讲img烧录到板子的SD中,并让板子从SD启动就好。
方案一:
使用自己编译的img,直接dd刻录。http://www.lemaker.org/resources/9-39/banana_pi_quick_start_guide.html
Run the sudo dd bs=4M if=[path]/[imagename] of=/dev/sdx command to write image file to SD card. Wait patiently to successfully complete writing. Please note that block size set to 4M will work most of the time, if not, please try 1M, although 1M will take considerably longer.
方案二:
使用官方提供的镜像,uboot
一般情况我们需要手动分区,然后在对于每个分区进行操作,比如我们操作的SD卡是/dev/sdb
因为这个板子是全智A20,我们要根据官方的指导文件,进行分区。

首先fdisk /dev/sdb
进入使用o清除所有分区!
所以我们必须把SD卡的前1M空出来,然后存放uboot的SPL头,放在seek=8 bs=1024处,seek即为偏移量。然后在开始地址1024后存放uboot,uboot烧写完成,再分一个区存放ext4,也就是rootfs的Openwrt实体!
$dd if=/dev/zero of=/dev/sda bs=1M count=1 $dd if=openwrt-sunxi-Bananapi-u-boot-with-spl.bin of=/dev/sda bs=1024 seek=8 //之后使用fdisk分区,分成sdb1 sdb2 $fdisk /dev/sda
a)n->默认p->默认1->默认2048->34815
b)n->默认p->默认2->默认34816->默认剩余全部,再次p查看分区,但sdb1要改为fat格式; t更改分区类型,指定分区号,指定类型,L查看所有分区类型,fat的类型编号为c;w保存所有操作。
$mkfs.vfat /dev/sdb1 $mkfs.ext4 /dev/sdb2 $mount /dev/sdb1 /media/pi/1 $mount /dev/sdb2 /media/pi/2
我们需要的文件主要是
openwrt-sunxi-root.ext4
openwrt-sunxi-uImage
sun7i-a20-bananapi.dtb
openwrt-sunxi-Bananapi-u-boot-with-spl.bin
openwrt-sunxi-Bananapi-uEnv.txt
在1中我们主要是在1中新建一个文件,打开后添加openwrt-sunxi-Bananapi-uEnv.txt中的内容,保存为boot.cmd,然后
$mkimage -C none -A arm -T script -d boot.cmd boot.scr
在文件夹1中直接拷贝sun7i-a20-bananapi.dtb和openwrt-sunxi-uImage文件,两个文件的文件名要和刚才boot.cmd中的相同;
$dd if=/xxx/openwrt-sunxi-root.ext4 of=/dev/sdb2 bs=1M //xxx替换为自己的路径
然后烧写完毕,我们可以连接串口进行通讯,需要特定的硬件,我主要应用实验室特殊的条件,直接请教硬件大神!
之后我们可以使用ssh方式将板子与电脑直接使用网线连接!
之后就可以随意配置了。
附一张烧写好的板子,由于官方送了外壳,我基本就把他安装好了。运行状态图:

———————–
官方默认不编译的库,我们就要手动编译,我们首先下载这个板子的官方编译环境具体包的名字:OpenWrt-SDK-sunxi-for-linux-x86_64-gcc-4.8-linaro_uClibc-0.9.33.2.tar.bz2
然后把需要的package放到解压后这个文件夹下的package下,使用make menuconfig编译。编译完成后在bin下面会找到ipk包!
然后我们可以通过vsftpd方式传到路由器中,通过opkg install 安装。至于如果你需要基于luci-app-*的包,需要搜索或者到http://sourceforge.net/projects/openwrt-dist/查找。
之后我们登陆路由器官方网页界面进行配置。这个需要我们指定路由器网关!
关于shadowsockets 与 chinadns设置:
http://www.tuicool.com/articles/fauueym
https://github.com/shadowsocks/openwrt-shadowsocks
https://github.com/aa65535/openwrt-chinadns
这次嵌入式烧板子,让我对于板子不再陌生,原来kernel与硬件接触如此紧密!