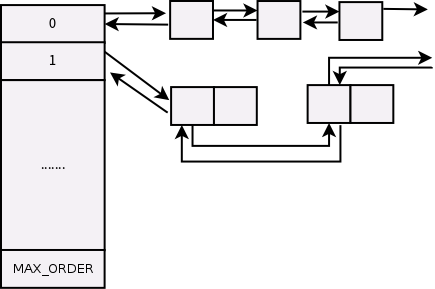
相对与页框慢速分配,快速分配而言。页框释放函数非常简单,主要的函数就是__free_pages()和__free_page()。很明显,类似于之前page分配的上层函数,也是层层wrapper。这里__free_page()是__free_pages()的包装。
#define __free_page(page) __free_pages((page), 0)
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page)) {
if (order == 0)
free_hot_cold_page(page, 0);
else
__free_pages_ok(page, order);
}
}
通过代码我们发现当要释放的页order==0,直接使用per-cpu缓存释放,大于0使用__free_pages_ok(page, order)释放。
这里kernel使用free_hot_cold_page() 方式释放order为0的页,这个函数只将不可移动页,可回收页和可移动页放入每个CPU页框高速缓存中,如果迁移类型不再这个范围,那么这个页要回收到伙伴系统中!这里的策略是:热页加入表头,冷页加入表尾。这个部分不在本文中叙述,查看代码便知。
来看__free_pages_ok()函数,这个函数也是一个wrapper函数,主要用来检查参数是否正确,做一些释放page前的准备工作。当一切就绪后就会调用free_one_page()函数。大致调用关系是:
static void __free_pages_ok(struct page *page, unsigned int order)
{
....
free_one_page(page_zone(page), page, pfn, order, migratetype);
....
}
static void free_one_page(struct zone *zone,
struct page *page, unsigned long pfn,
unsigned int order,
int migratetype)
{
unsigned long nr_scanned;
spin_lock(&zone->lock);
...
__free_one_page(page, pfn, zone, order, migratetype);
spin_unlock(&zone->lock);
}
在调用__free_one_page()之前,kernel换回更新当前zone下面page状态:更新当前内存管理区的空闲页面数,也就是更新zone下面的vm_stat数组,这个数组用于统计当前内存信息。
在核心函数__free_one_page()中,这个函数主要完成page的回收,完成页的合并,首先要获取要释放page的page index
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype)
{
unsigned long page_idx;
unsigned long combined_idx;
unsigned long uninitialized_var(buddy_idx);
struct page *buddy;
int max_order = MAX_ORDER;
...
page_idx = pfn & ((1 << max_order) - 1);
...
while (order < max_order - 1) {
buddy_idx = __find_buddy_index(page_idx, order);
buddy = page + (buddy_idx - page_idx);
if (!page_is_buddy(page, buddy, order))
break;
if (page_is_guard(buddy)) {
clear_page_guard_flag(buddy);
set_page_private(buddy, 0);
if (!is_migrate_isolate(migratetype)) {
__mod_zone_freepage_state(zone, 1 << order,
migratetype);
}
} else {
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
rmv_page_order(buddy);
}
combined_idx = buddy_idx & page_idx;
page = page + (combined_idx - page_idx);
page_idx = combined_idx;
order++;
}
set_page_order(page, order);
if ((order < MAX_ORDER-2) && pfn_valid_within(page_to_pfn(buddy))) {
struct page *higher_page, *higher_buddy;
combined_idx = buddy_idx & page_idx;
higher_page = page + (combined_idx - page_idx);
buddy_idx = __find_buddy_index(combined_idx, order + 1);
higher_buddy = higher_page + (buddy_idx - combined_idx);
if (page_is_buddy(higher_page, higher_buddy, order + 1)) {
list_add_tail(&page->lru,
&zone->free_area[order].free_list[migratetype]);
goto out;
}
list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);
out:
zone->free_area[order].nr_free++;
}
然遍历当前order到max-order所有阶,使用__page_find_buddy()找到当前page_idx的伙伴buddy_idx,然后根据idx偏移量,找到目标buddy。后将这个buddy从list删除,更新nr_free数量。删除buddy标记。最后使用 buddy_idx & page_idx 获取合并后的combined_idx。由于page永远都指向要释放页框块的首页框描述符,所以讲这个combined_idx赋值给page_idx。最后将order+1,然后通过set_page_order()设置这个page的各种信息。
在最新的源码里面,还会判断是否这个page是否是最大的页,如果找到则继续合并,并将合并后page放到list tail中,最后将当前order下的nr_order++。
最后我们来看__find_buddy_index()函数
static inline unsigned long
__find_buddy_index(unsigned long page_idx, unsigned int order)
{
return page_idx ^ (1 << order);
}
这个函数用来查找buddy的index,这个函数非常简单。
综上所述,所以整个页框分配的核心就是那个while循环,我们可以把页框释放当成页框分裂的逆过程,也就是回收order大于0的页:
举例:
page_idx = 10 -> buddy_idx = 11 -> combined_idx = 10
page_idx = 10 -> buddy_idx = 8 -> combined_idx = 8
page_idx = 8 -> buddy_idx = 12 -> combined_idx = 8
page_idx = 8 -> buddy_idx = 0 -> combined_idx = 0
->无法继续进行->结束
这就是那些位操作的实际含义,page_idx以二倍速率寻找buddy page然后合并,至此伙伴系统回收页框完毕。
参考: