CNN(Convolutional Neural Networks)是当下最火的一种神经网络,主要用来识别图像。CNN由三部分组成:Convolutional Layer, Pooling Layer 和 Fully-Connected Layer,卷积层和池化都是CNN特有的,全连接层是传统的神经网络。
整个网络流程就是 [INPUT – CONV – RELU – POOL – FC],其中CONV-RELU-POOL可以添加很多层,如图所示
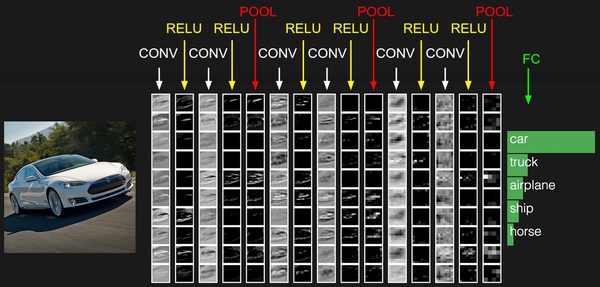
 举个例子:
举个例子:
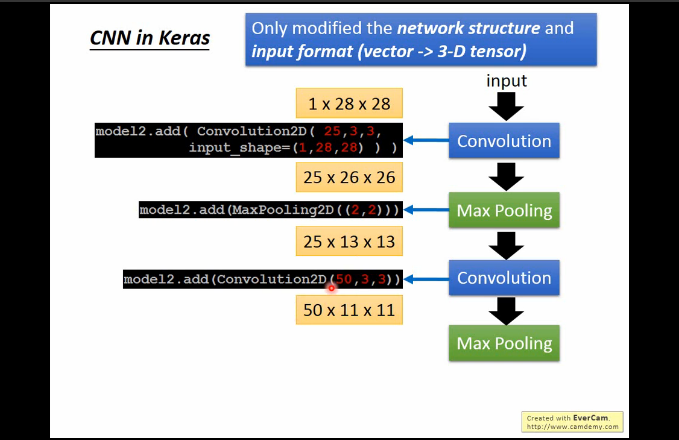
- 输入的数据都是28x28x1的图像,意思就是长宽都是28的pixel,并且是单通道图像。
- 卷积层中,神经元与输入层中的一个局部区域相连,每个神经元都计算自己与输入层相连的小块区域与自己权重的内积。卷积层会计算所有神经元的输出。如果我们使用25个filter[3x3x25],每个filter是得到的输出数据体的维度就是[26x26x25]。
- ReLU层将会逐个元素地进行激活函数操作,比如使用以0为阈值的max(0,x)作为激活函数。该层对数据尺寸没有改变,还是[26x26x25]。
- 汇聚层在在空间维度(宽度和高度)上进行降采样(downsampling)操作,其实也就是POOL层[2×2],数据尺寸变为[13x13x25]。
- 然后可以再次进行卷积、ReLU和Pool。
- 全连接层将会计算分类评分,数据尺寸变为[1x1x10],其中10个数字对应的就是CIFAR-10中10个类别的分类评分值,全连接层与常规神经网络一样,其中每个神经元都与前一层中所有神经元相连接。
最开始卷积的维度变化让我很头疼,看了好久才理解。总结下面公式:
- 输入数据体的尺寸为W1 * H1 * D1
- 4个参数:
filter的数量K
filter的空间尺寸F
步长stride S
零填充数量(the amount of zero padding)P - 输出数据体的尺寸为W2 * H2 * D2 ,其中:
W2=(W1-F+2P)/S+1
H2=(H1-F+2P)/S+1 (宽度和高度的计算方法相同)
D2=K
由于参数共享,每个滤波器包含F * F *D1个权重,卷积层一共有F * F * D1 K个权重和K个偏置。
每进行一次卷积,图像的深度就增加一倍,深度与filter的数量K紧密相关!
常见的设置是F=3,S=1,P=1,零填充数量就是为了让输入图像长宽变为偶数(其实就是在图像外围填充0),例如是32、64、128等,而使用S=1的步长,是因为使得空间维度的降采样全部由Pooling层负责,卷积层只负责对输入数据体的深度进行变换。
使用这些参数需要考虑到内存的占用率,比如使用64个尺寸为3×3的滤波器对【224x224x3】的图像进行卷积,零填充为1,步长为1,那么得到的激活数据体尺寸是[224x224x64]。这个数量就是一千万的数据特征,或者就是72MB的内存!
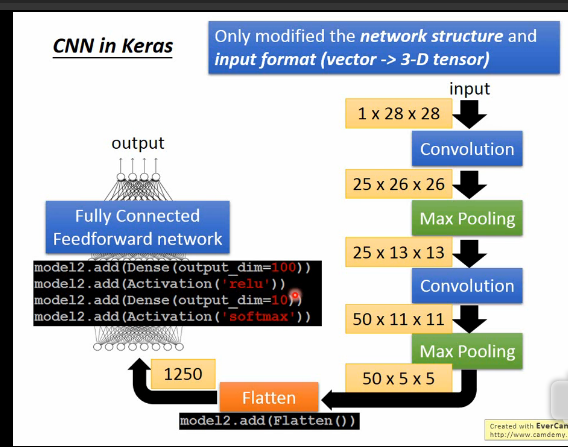
第二次池化后,使用Flatten,压扁这个数据集合,建立二层全连接网络,第一层神经元数100,第二层为10。
参考:
http://cs231n.github.io/convolutional-networks/
http://cs231n.stanford.edu/syllabus.html
http://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html