0 前言
在Linux中,主要是通过fork的方式产生新的进程,我们都知道每个进程都在 内核对应一个PCB块,内核通过对PCB块的操作做到对进程的管理。在Linux内核中,PCB对应着的结构体就是task_struct,也就是所谓的进程描述符(process descriptor)。该数据结构中包含了程相关的所有信息,比如包含众多描述进程属性的字段,以及指向其他与进程相关的结构体的指针。因此,进程描述符内部是比较复杂的。这个结构体的声明位于include/linux/sched.h中。
task_struct中有指向mm_struct结构体的指针mm,也有指向fs_struct结构体的指针fs,这个结构体是对进程当前所在目录的描述;也有指向files_struct结构体的指针files,这个结构体是对该进程已打开的所有文件进行描述。这里我们要注意进程在运行期间中可能处于不同的进程状态,例如:TASK_RUNNING/TASK_STOPPED/TASK_TRACED 等
1 fork调用
在用户态下,使用fork()创建一个进程。除了这个函数,新进程的诞生还可以分别通过vfork()和clone()。fork、vfork和clone三个API函数均由glibc库提供,它们分别在C库中封装了与其同名的系统调用fork()。这几个函数调用对应不同场景,有些时候子进程需要拷贝父进程的整个地址空间,但是子进程创建后又立马去执行exec族函数造成效率低下。
- 写时拷贝满足了这种需求,同时减少了地址空间复制带来的问题。
- vfork 则是创建的子进程会完全共享父进程的地址空间,甚至是父进程的页表项,父子进程任意一方对任何数据的修改使得另一方都可以感知到。
- clone函数创建子进程时灵活度比较大,因为它可以通过传递不同的参数来选择性的复制父进程的资源
系统调用fork、vfork和clone在内核中对应的服务例程分别为sys_fork(),sys_vfork()和sys_clone()。例如sys_fork()声明如下(arch/x86/kernel/process.c):
int sys_fork(struct pt_regs *regs)
{
return do_fork(SIGCHLD, regs->sp, regs, 0, NULL, NULL);
}
int sys_vfork(struct pt_regs *regs)
{
return do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, regs->sp, regs, 0,
NULL, NULL);
}
sys_clone(unsigned long clone_flags, unsigned long newsp,
void __user *parent_tid, void __user *child_tid, struct pt_regs *regs)
{
if (!newsp)
newsp = regs->sp;
return do_fork(clone_flags, newsp, regs, 0, parent_tid, child_tid);
}
可以看到do_fork()均被上述三个服务函数调用。do_fork()正是kernel创建进程的核心()。通过分析调用过程如下,其中我分析的是最新版4.X Linux源码,在i386体系结构中,采取0x80中断调用syscall:
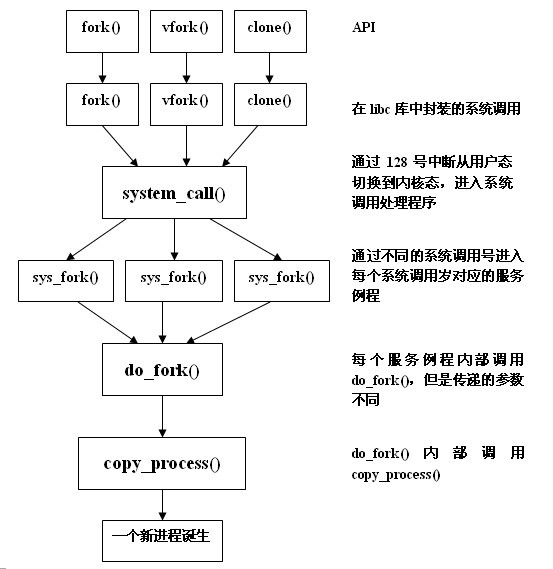
从图中可以看到do_fork()和copy_process()是本文的主要分析对象。
do_fork函数的主要就是复制原来的进程成为另一个新的进程,在一开始,该函数定义了一个task_struct类型的指针p,用来接收即将为新进程(子进程)所分配的进程描述符。但是这个时候要检查clone_flags是否被跟踪就是ptrace,ptrace是用来标示一个进程是否被另外一个进程所跟踪。所谓跟踪,最常见的例子就是处于调试状态下的进程被debugger进程所跟踪。ptrace字段非0时说明debugger程序正在跟踪父进程,那么接下来通过fork_traceflag函数来检测子进程是否也要被跟踪。如果trace为1,那么就将跟踪标志CLONE_PTRACE加入标志变量clone_flags中。没有的话才可以进程创建,也就是copy_process()。
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct task_struct *p;
int trace = 0;
long nr;
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
这条语句要做的是整个创建过程中最核心的工作:通过copy_process()创建子进程的描述符,并创建子进程执行时所需的其他数据结构,最终则会返回这个创建好的进程描述符。因为copy_process()函数过于巨大,所以另外开辟一篇文章讲解该函数实现。
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls);
如果copy_process函数执行成功,那么将继续下面的代码。定义了一个完成量vfork,之后再对vfork完成量进行初始化。如果使用vfork系统调用来创建子进程,那么必然是子进程先执行。原因就是此处vfork完成量所起到的作用:当子进程调用exec函数或退出时就向父进程发出信号。此时,父进程才会被唤醒;否则一直等待。
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
下面通过wake_up_new_task函数使得父子进程之一优先运行;如果设置了ptrace,那么需要告诉跟踪器。如果CLONE_VFORK标志被设置,则通过wait操作将父进程阻塞,直至子进程调用exec函数或者退出。
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
如果copy_process()在执行的时候发生错误,则先释放已分配的pid;再根据PTR_ERR()的返回值得到错误代码,保存于pid中。 返回pid。这也就是为什么使用fork系统调用时父进程会返回子进程pid的原因。
} else {
nr = PTR_ERR(p);
}
return nr;
}
参考:
http://cs.lmu.edu/~ray/notes/linuxsyscalls/
http://www.x86-64.org/documentation/abi.pdf
http://www.tldp.org/LDP/tlk/ds/ds.html