Pod
- Pod是K8s中最小的单元
- 一组容器的集合
- 共享网络【一个Pod中的所有容器共享同一网络】
- 生命周期是短暂的(服务器重启后,就找不到了)
Volume
- 声明在Pod容器中可访问的文件目录
- 可以被挂载到Pod中一个或多个容器指定路径下
- 支持多种后端存储抽象【本地存储、分布式存储、云存储】
Controller
- 确保预期的pod副本数量【ReplicaSet】
- 无状态应用部署【Deployment】
- 无状态就是指,不需要依赖于网络或者ip
- 有状态应用部署【StatefulSet】
- 有状态需要特定的条件
- 确保所有的node运行同一个pod 【DaemonSet】
- 一次性任务和定时任务【Job和CronJob】
Deployment
- 定义一组Pod副本数目,版本等
- 通过控制器【Controller】维持Pod数目【自动回复失败的Pod】
- 通过控制器以指定的策略控制版本【滚动升级、回滚等】
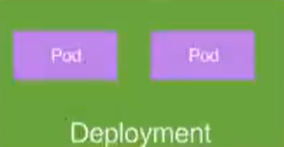
Service
- 定义一组pod的访问规则
- Pod的负载均衡,提供一个或多个Pod的稳定访问地址
- 支持多种方式【ClusterIP、NodePort、LoadBalancer】
Label
label:标签,用于对象资源查询,筛选
Namespace
命名空间,逻辑隔离
- 一个集群内部的逻辑隔离机制【鉴权、资源】
- 每个资源都属于一个namespace
- 同一个namespace所有资源不能重复
- 不同namespace可以资源名重复
API
我们通过Kubernetes的API来操作整个集群
同时我们可以通过 kubectl 、ui、curl 最终发送 http + json/yaml 方式的请求给API Server,然后控制整个K8S集群,K8S中所有的资源对象都可以采用 yaml 或 json 格式的文件定义或描述
如下:使用yaml部署一个nginx的pod

完整流程
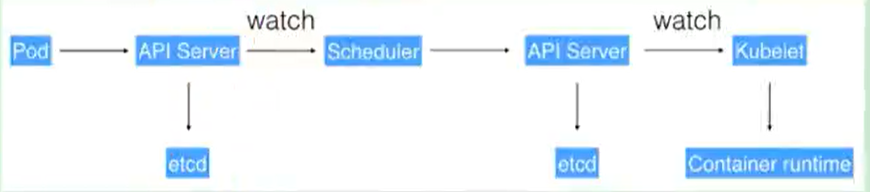
- 通过Kubectl提交一个创建RC(Replication Controller)的请求,该请求通过APlserver写入etcd
- 此时Controller Manager通过API Server的监听资源变化的接口监听到此RC事件
- 分析之后,发现当前集群中还没有它所对应的Pod实例
- 于是根据RC里的Pod模板定义一个生成Pod对象,通过APIServer写入etcd
- 此事件被Scheduler发现,它立即执行执行一个复杂的调度流程,为这个新的Pod选定一个落户的Node,然后通过API Server讲这一结果写入etcd中
- 目标Node上运行的Kubelet进程通过APiserver监测到这个”新生的Pod.并按照它的定义,启动该Pod并任劳任怨地负责它的下半生,直到Pod的生命结束
- 随后,我们通过Kubectl提交一个新的映射到该Pod的Service的创建请求
- ControllerManager通过Label标签查询到关联的Pod实例,然后生成Service的Endpoints信息,并通过APIServer写入到etod中,
- 接下来,所有Node上运行的Proxy进程通过APIServer查询并监听Service对象与其对应的Endponts信息,建立一个软件方式的负载均衡器来实现Service访问到后端Pod的流量转发功能