对于内核空间,根据不同的映射规则,可以将整个内核空间划分为四大部分:物理内存映射区、vmalloc区、永久内核映射区和固定映射的线性地址区域。这里我们只来谈谈vmalloc()的分配。首先我们来看一下之前的一个图:
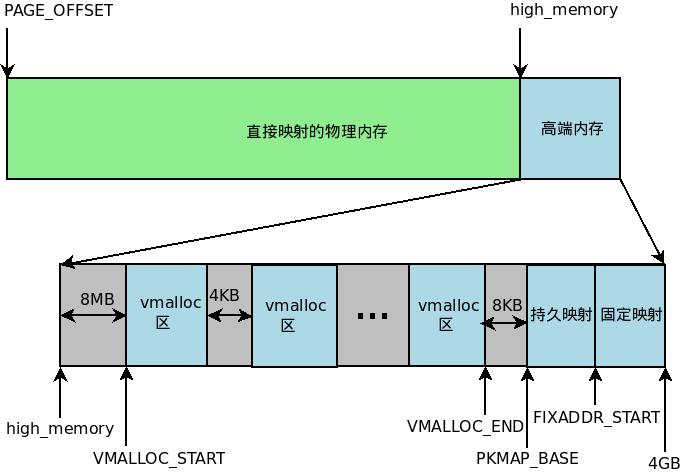
vmalloc()区域是从VMALLOC_START开始,一直到VMALLOC_END结束,中间有PAGE_SIZE大小的guard_page作为保护,以防止防止非法的内存访问,内核中使用vm_struct结构来表示每个vmalloc区,也就是说,每次调用vmalloc()函数在内核中申请一段连续的内存后,都对应着一个vm_struct,kernel 中所有的vmalloc区组成一个链表,链表头指针为vmlist
static struct vm_struct *vmlist __initdata;
struct vm_struct {
struct vm_struct *next;
void *addr;
unsigned long size;
unsigned long flags;
struct page **pages;
unsigned int nr_pages;
phys_addr_t phys_addr;
const void *caller;
};
这里我们只介绍几个重要的字段:
next:所有的vm_struct结构组成一个vmlist链表,该字段指向下一个节点;
addr:代表这段子区域的起始地址;
size:表示区域的大小;
flags:表示该非连续内存区的类型,VM_ALLOC表示由vmalloc()映射的内存区,VM_MAP表示通过vmap()映射的内存区,VM_IOREMAP表示通过ioremap()将硬件设备的内存映射到内核的一段内存区;
pages:指针数组,该数组的成员是struct page*类型的指针,每个成员都关联一个映射到该虚拟内存区的物理页框;
nr_pages:pages数组中page结构的总数;
phys_addr:通常为0,当使用ioremap()映射一个硬件设备的物理内存时才填充此字段;
caller:表示一个返回地址;
vmalloc()的实现
vmalloc()内部封装了很多层函数,调用层次就是:vmalloc()-> __vmalloc_node_flags() -> __vmalloc_node() -> __vmalloc_node_range() ,通过这几层调用,就会向最终的__vmalloc_node_range()传入很多参数,GFP_KERNEL|__GFP_HIGHMEM表明内存管理子系统将从高端内存区(ZONE_HIGHMEM)中分配内存空间;NUMA_NO_NODE表示当前不是NUMA架构。
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE,
GFP_KERNEL | __GFP_HIGHMEM);
}
static inline void *__vmalloc_node_flags(unsigned long size,
int node, gfp_t flags)
{
return __vmalloc_node(size, 1, flags, PAGE_KERNEL,
node, __builtin_return_address(0));
}
static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot,
int node, const void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, node, caller);
}
这里我们进入真正分配vmalloc区域的函数__vmalloc_node_range(),我们只要关注第三个第四个参数,就是vm区域的开始地址与结束地址,__vmalloc_node_range()一开始会先修正一下size对齐,PAGE_ALIGN将size的大小修改成页大小的倍数。进行size合法性的检查,如果size为0,或者size所占页框数大于系统当前空闲的页框数(totalram_pages),将返回NULL,申请失败。
如果分配的内存区大小合法,__get_vm_area_node()中的alloc_vmap_area()将在整个非连续内存区中查找一个size大小的子内存区。该函数先遍历整个vmlist链表,依次比对每个vmalloc区,直到找到满足要求的子内存区结束。在这里面还做好了内核页表的映射等操作。
建立好了vm_struct 结构,下面就要分配使用__vmalloc_area_node()为这个vmalloc内存区分配真正的物理页。
void *__vmalloc_node_range(unsigned long size, unsigned long align,
unsigned long start, unsigned long end, gfp_t gfp_mask,
pgprot_t prot, int node, const void *caller)
{
struct vm_struct *area;
void *addr;
unsigned long real_size = size;
size = PAGE_ALIGN(size);
if (!size || (size >> PAGE_SHIFT) > totalram_pages)
goto fail;
area = __get_vm_area_node(size, align, VM_ALLOC | VM_UNINITIALIZED,
start, end, node, gfp_mask, caller);
if (!area)
goto fail;
addr = __vmalloc_area_node(area, gfp_mask, prot, node);
if (!addr)
return NULL;
...
return addr;
....
__vmalloc_area_node()的实现
首先根据传入的vm_struct *area 获取要分配的物理页大小,这里的大小包括了guard_page,所以要在get_vm_area_size()减去这个PAGE_SIZE,翻译过来就是nr_pages = (area->size – PAGE_SIZE) >> PAGE_SHIFT;抹去低位,也就是要分配的page数,然后nr_pages * sizeof(struct page *)也就是真正的物理page大小。
根据这个array_size大小,我们可以判断要分配的是大于PAGE_SIZE还是小于PAGE_SIZE,大于的话就递归分配pages数组,小于的话,通过kmalloc_node()为pages数组分配一段连续的空间,这段空间位于内核空间的物理内存线性映射区。然后将分配好的page加入area,更新area中的pages。
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, int node)
{
const int order = 0;
struct page **pages;
unsigned int nr_pages, array_size, i;
const gfp_t nested_gfp = (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO;
const gfp_t alloc_mask = gfp_mask | __GFP_NOWARN;
nr_pages = get_vm_area_size(area) >> PAGE_SHIFT;
array_size = (nr_pages * sizeof(struct page *));
area->nr_pages = nr_pages;
/* Please note that the recursion is strictly bounded. */
if (array_size > PAGE_SIZE) {
pages = __vmalloc_node(array_size, 1, nested_gfp|__GFP_HIGHMEM,
PAGE_KERNEL, node, area->caller);
area->flags |= VM_VPAGES;
} else {
pages = kmalloc_node(array_size, nested_gfp, node);
}
area->pages = pages;
接下来通过一个循环为pages数组中的每个页面描述符分配真正的物理页框。page结构并不是代表一个具体的物理页框,只是用来描述物理页框的数据结构而已。如果node未指定物理内存所在节点,那么alloc_page()分配一个页框,并将该页框对应的页描述符指针赋值给page临时变量;否则通过alloc_pages_node()在指定的节点上分配物理页框。接着将刚刚分配的物理页框对应的页描述符赋值给pages数组的第i个元素。这里一旦某个物理页框分配失败则直接返回NULL,表示本次vmalloc()操作失败。
for (i = 0; i < area->nr_pages; i++) {
struct page *page;
if (node == NUMA_NO_NODE)
page = alloc_page(alloc_mask);
else
page = alloc_pages_node(node, alloc_mask, order);
if (unlikely(!page)) {
/* Successfully allocated i pages, free them in __vunmap() */
area->nr_pages = i;
goto fail;
}
area->pages[i] = page;
if (gfp_mask & __GFP_WAIT)
cond_resched();
}
if (map_vm_area(area, prot, pages))
goto fail;
return area->addr;
fail:
warn_alloc_failed(gfp_mask, order,
"vmalloc: allocation failure, allocated %ld of %ld bytes\n",
(area->nr_pages*PAGE_SIZE), area->size);
vfree(area->addr);
return NULL;
}
这里当kernel分配完page,并将信息输入到area中后,这些分散的页框并没有映射到area所代表的那个连续vmalloc区中。使用map_vm_area()将完成映射,它依次修改内核页表,将pages数组中的每个页框分别映射到连续的vmalloc区中。
map_vm_area()工作原理会在下一篇文章中说明!