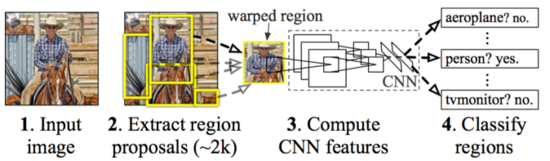
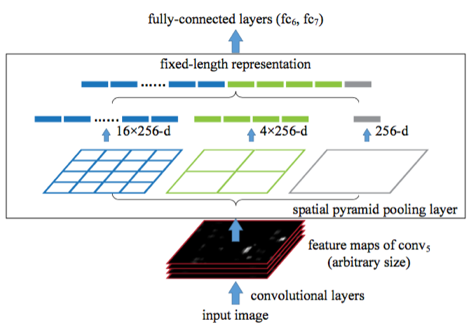
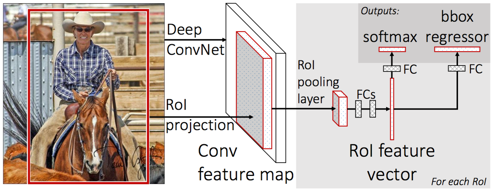
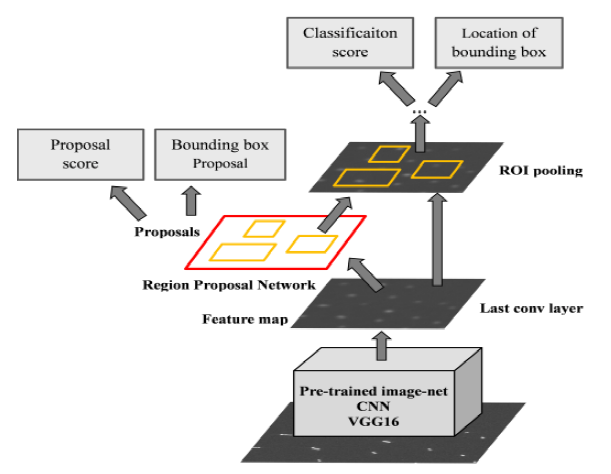
上篇对于三大RCNN算法进行了阐述,算法首要都必须提取整幅图的特征向量,目前性能比较好的神经网络是ResNet。ResNet使用了深度残差网络(Deep Residual Network),这种网络的发明的背景在于网络的层数在不断增加的情况下出现识别率降低的问题。
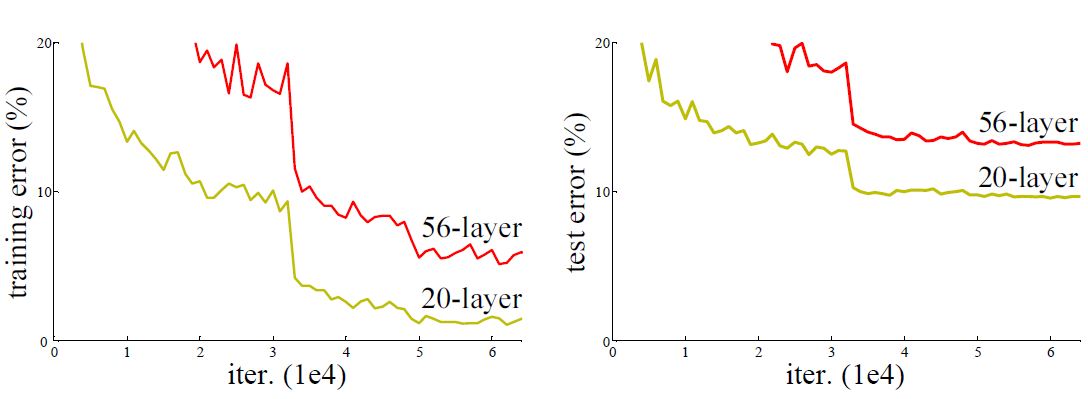
Deep Residual Network采用在层与层之间添加shortcut,即每层的输出不是传统神经网络当中输入的映射,而是映射和输入的叠加。
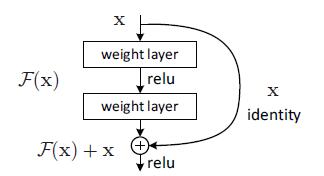
网上很多观点都倾向于梯度消失,即对网络做BP推导的话,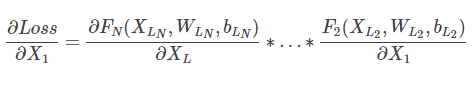
本来每个子项就特别小,再乘以更小的子项导致梯度趋近于0,而Deep Residual Network采用添加路径的方式将X1和XL连接起来,导致偏导置于一个比较大的数,在BP过程中,梯度不容易消失。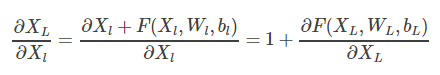
学术界对于出现这种问题的根源有不同的看法,我倾向这种增加路径的方式非常类似于Dropout,一个是增加路径,一个是随机减少路径,实际上效果来自于训练层数的减少,实际每次训练网络结构层数少于网络最大层数。
目前在我算法里,我使用的是ResNet50,50就是包含50层Conv卷积,ResNet50在网上有现成的model和weights,不过这里为了加深理解提供部分基于Keras的模型代码和模型结构图示。
x = ZeroPadding2D((3, 3))(img_input)
x = Convolution2D(64, (7, 7), strides=(2, 2), name='conv1', trainable = trainable)(x)
x = FixedBatchNormalization(axis=bn_axis, name='bn_conv1')(x)
x = Activation('relu')(x)
x = MaxPooling2D((3, 3), strides=(2, 2))(x)
x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1), trainable = trainable)
x = identity_block(x, 3, [64, 64, 256], stage=2, block='b', trainable = trainable)
x = identity_block(x, 3, [64, 64, 256], stage=2, block='c', trainable = trainable)
x = conv_block(x, 3, [128, 128, 512], stage=3, block='a', trainable = trainable)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='b', trainable = trainable)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='c', trainable = trainable)
x = identity_block(x, 3, [128, 128, 512], stage=3, block='d', trainable = trainable)
x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a', trainable = trainable)
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b', trainable = trainable)
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c', trainable = trainable)
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d', trainable = trainable)
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e', trainable = trainable)
x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f', trainable = trainable)
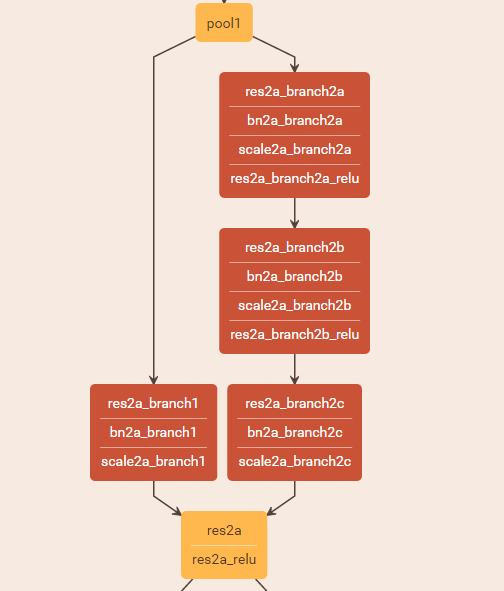
上图只是针对其中一个conv_block,conv_block分出两个分支,一个分支卷积一次,一个分支卷积3次,然后在res2a处将两个分支Add。identity_block则是直接将输入和三次卷积结果Add。
http://blog.csdn.net/superCally/article/details/55671064
https://my.oschina.net/yilian/blog/667900
https://arxiv.org/pdf/1605.06431.pdf