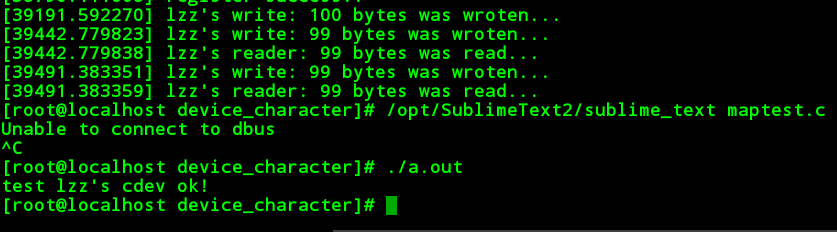
我们都知道在linux里面存在块设备与字符设备。我们这里是设计的字符驱动,在不久,我会加入支持阻塞的功能。
我们可以通过查看cat /proc/device查看已注册的设备
[lzz@localhost device_character]$ cat /proc/devices Character devices: 1 mem 4 /dev/vc/0 4 tty 4 ttyS 5 /dev/tty 5 /dev/console 5 /dev/ptmx 7 vcs 10 misc 13 input 14 sound 21 sg 29 fb 99 ppdev 116 alsa 128 ptm 136 pts 162 raw 180 usb 188 ttyUSB 189 usb_device 202 cpu/msr 203 cpu/cpuid 226 drm 250 hidraw 251 usbmon 252 bsg 253 watchdog 254 rtc Block devices: 259 blkext 8 sd 9 md 11 sr 65 sd 66 sd 67 sd 68 sd 69 sd 70 sd 71 sd 128 sd 129 sd 130 sd 131 sd 132 sd 133 sd 134 sd 135 sd 253 device-mapper 254 mdp
我们选取一个231作为我们字符设备号,别的不废话,上代码.
字符设备驱动程序:
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/string.h>
#include <linux/errno.h>
#include <linux/mm.h>
#include <linux/vmalloc.h>
#include <linux/slab.h>
#include <asm/io.h>
#include <linux/mman.h>
#include <linux/uaccess.h>
MODULE_AUTHOR("lzz");
MODULE_LICENSE("GPL");
#define MYCDEV_MAJOR 231 /*the predefined mycdev's major devno*/
#define MYCDEV_SIZE 100
static char kernel_buf[MYCDEV_SIZE];
static int mycdev_open(struct inode *inode, struct file *fp)
{
return 0;
}
static int mycdev_release(struct inode *inode, struct file *fp)
{
return 0;
}
static ssize_t mycdev_read(struct file *fp, char __user *buf, size_t size, loff_t *pos)
{
unsigned long p = *pos;
unsigned int count = size;
// int i;
if(p >= MYCDEV_SIZE)
return -1;
if(count > MYCDEV_SIZE)
count = MYCDEV_SIZE - p;
if (copy_to_user(buf, kernel_buf, count) != 0)
{
printk("read error!\n");
return -1;
}
printk("lzz's reader: %d bytes was read...\n", count);
return count;
}
static ssize_t mycdev_write(struct file *fp, const char __user *buf, size_t size, loff_t *pos)
{
unsigned long p = *pos;
unsigned int count = size;
int ret =0;
if(copy_from_user(kernel_buf+p,buf,count))
ret = -EFAULT;
else
{
*pos+=count;
ret = count;
printk("lzz's write: %d bytes was wroten...\n", count);
}
return ret;
}
/*filling the mycdev's file operation interface in the struct file_operations*/
static const struct file_operations mycdev_fops =
{
.owner = THIS_MODULE,
.read = mycdev_read,
.write = mycdev_write,
.open = mycdev_open,
.release = mycdev_release,
};
/*module loading function*/
static int __init mycdev_init(void)
{
int ret;
printk("mycdev module is staring..\n");
ret=register_chrdev(MYCDEV_MAJOR,"lzz_cdev",&mycdev_fops);
if(ret<0)
{
printk("register failed..\n");
return 0;
}
else
{
printk("register success..\n");
}
return 0;
}
/*module unloading function*/
static void __exit mycdev_exit(void)
{
printk("mycdev module is leaving..\n");
unregister_chrdev(MYCDEV_MAJOR,"lzz_cdev");
}
module_init(mycdev_init);
module_exit(mycdev_exit);
Makefile文件:
obj-m:= map_driver.o CURRENT_PATH:=$(shell pwd) LINUX_KERNEL:=$(shell uname -r) LINUX_KERNEL_PATH:=/lib/modules/$(LINUX_KERNEL)/build all: make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules clean: make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
用户态测试程序:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
int testdev;
int i, ret;
char buf[100]="test lzz's cdev ok!";
char buff[100];
testdev = open("/dev/mycdev", O_RDWR);
if (-1 == testdev) {
printf("cannot open file.\n");
exit(1);
}
write(testdev,buf,sizeof(buf)-1);
if ((ret = read(testdev, buff, sizeof(buff)-1)) < 0) {
printf("read error!\n");
exit(1);
}
printf("%s\n", buff);
close(testdev);
return 0;
}
使用方法:
1.make编译map_driver.c文件,并插入到内核;
2.通过cat /proc/devices 查看系统中未使用的字符设备主设备号,比如当前231未使用;
3.创建设备文件结点:sudo mknod /dev/mycdev c 231 0;具体使用方法通过man mknod命令查看;
4.修改设备文件权限:sudo chmod 777 /dev/mycdev;(可选)
5.以上成功完成后,编译本用户态测试程序;运行该程序查看结果;
6.通过dmesg查看日志信息;