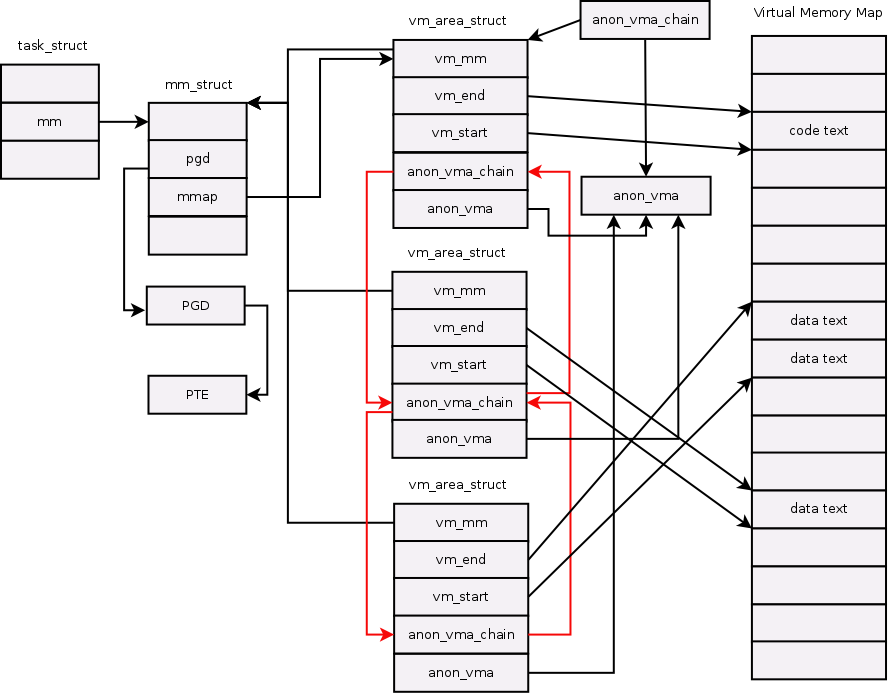
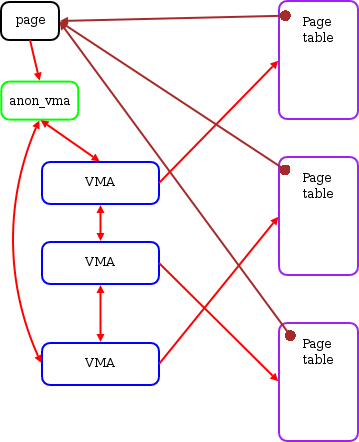
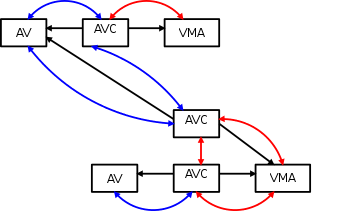
Update 2015-6-3
最近项目需要使用到docker进行live migration。之前接触过lxc,所以这时两款原理上相同的容器虚拟化产品。我是在fedora 20下使用这个产品,在fedora20的官方仓库中有一个重名的软件包docker,我们需要使用docker-io安装。
安装完成以后就可以通过systemctl 启动docker daemon
$ sudo systemctl start docker
如果想开机启动那么使用enable命令,当我们安装好docker以后,可以使用docker ps查看,在目前我使用的1.5版本docker。首先我先pull一个镜像:
[root@localhost contrib]# docker pull ubuntu:latest [root@localhost contrib]# docker images REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE ubuntu 14.04.2 07f8e8c5e660 2 weeks ago 188.3 MB ubuntu latest 07f8e8c5e660 2 weeks ago 188.3 MB ubuntu trusty 07f8e8c5e660 2 weeks ago 188.3 MB ubuntu trusty-20150427 07f8e8c5e660 2 weeks ago 188.3 MB ubuntu 14.04 07f8e8c5e660 2 weeks ago 188.3 MB busybox buildroot-2014.02 8c2e06607696 4 weeks ago 2.43 MB busybox latest 8c2e06607696 4 weeks ago 2.43 MB
pull完成以后,就可以通过docker images查看本机拥有的镜像,这时候我们使用docker run -d -t -i ubuntu /bin/sh可以启动镜像。
we’ve also passed in two flags: -t and -i. The -t flag assigns a pseudo-tty or terminal inside our new container and the -i flag allows us to make an interactive connection by grabbing the standard in (STDIN) of the container.
这时我们可以使用docker ps来查看本机启动的容器。
[root@localhost contrib]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f05df7249fea ubuntu:14.04 "/bin/bash" 9 seconds ago Up 6 seconds silly_hypatia
docker不同于lxc,主要使用一个64bit的id唯一标示一个容器,也是通过这个CONTAINER ID来标示,至于容器的停止,使用docker stop [CONTAINER ID] 或者是docker stop [NAMES]。删除一个镜像是docker rmi REPOSITORY:TAG即可,我们也可以使用别名机制来代替具体的CONTAINER ID。
[root@localhost contrib]# docker run -d -i -t --name busybox busybox:latest 3772693b1a82f996b296addf2f2ec00636535c81aa61730f66717d1311ae1b20 [root@localhost contrib]# docker stop busybox busybox [root@localhost contrib]# docker run -d -i -t --name busybox busybox:latest FATA[0000] Error response from daemon: Conflict. The name "busybox" is already in use by container 3772693b1a82. You have to delete (or rename) that container to be able to reuse that name. [root@localhost contrib]# docker run -d -i -t busybox:latest 5c331e6cddb00e134f39831ce1a6c5a9763c5ba60e1a41232503fce49fa17b09 [root@localhost contrib]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 5c331e6cddb0 busybox:buildroot-2014.02 "/bin/sh" 8 seconds ago Up 6 seconds elated_meitner f05df7249fea ubuntu:14.04 "/bin/bash" 3 hours ago Up 3 hours silly_hypatia
我们知道对于容器的动态迁移,利用pid进行C/R操作是十分有必要的,要想知道容器的pid,那么我们使用docker inspect busybox 查询当前容器的信息。我们看到这个容器的pid是768。
# docker inspect busybox
.....
"Path": "/bin/sh",
"ProcessLabel": "",
"ResolvConfPath": "/var/lib/docker/containers/f89a11d1cfe0037993dc4862ee218d59ccdcc4c7377fa4ed8946ed744226d8f6/resolv.conf",
"RestartCount": 0,
"State": {
"Error": "",
"ExitCode": 0,
"FinishedAt": "0001-01-01T00:00:00Z",
"OOMKilled": false,
"Paused": false,
"Pid": 768,
"Restarting": false,
"Running": true,
"StartedAt": "2015-06-02T22:48:09.975364683Z"
},
"Volumes": {},
"VolumesRW": {}
....
参考: