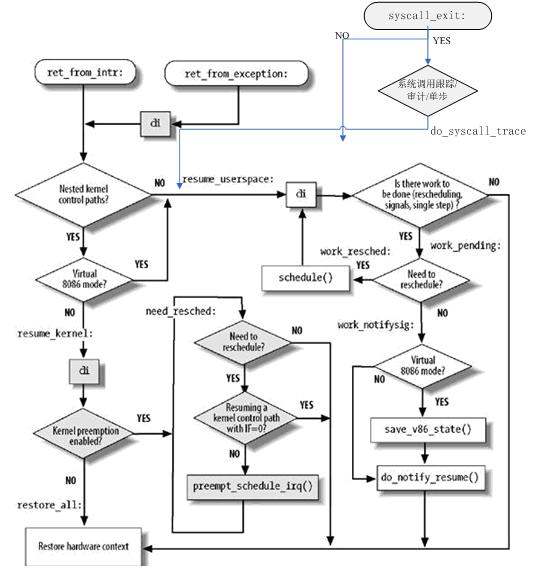
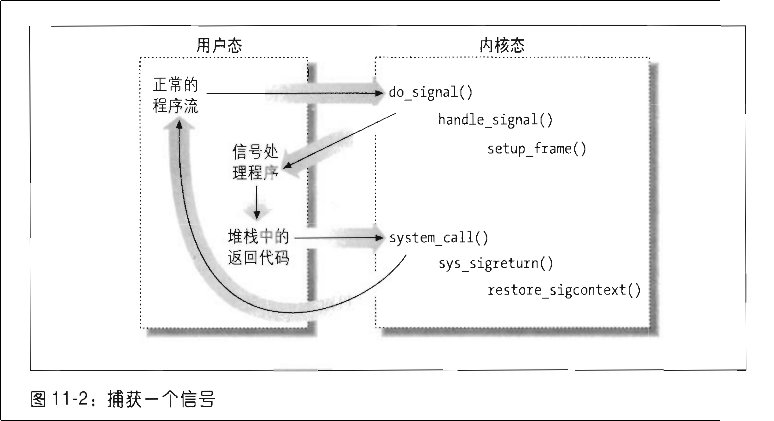
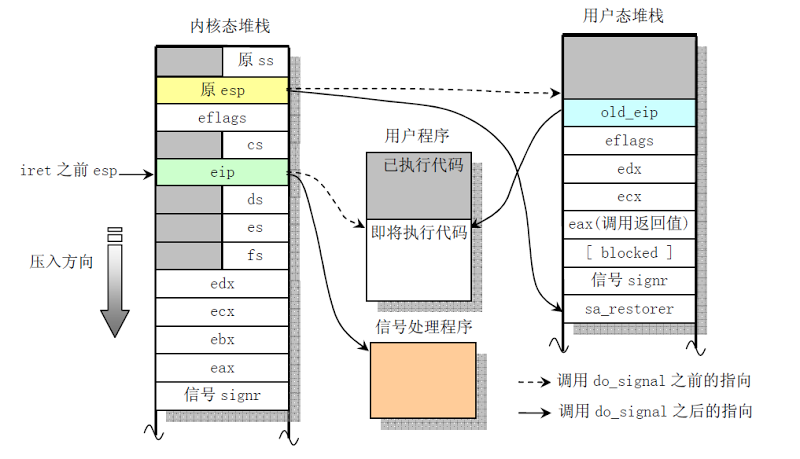
我们都知道用户态向内核态切换有三种方式:1:系统调用 2:中断 3:异常 。之前只是知道这个切换的原理,但是并没有仔细的从代码上面学习切换的过程。之前我学习了页表,但是内核页表与进程页表是割裂的,信号处理也是割裂的。这里我会结合用户态到内核态从代码进行分析。
这部分切换的函数是用汇编代码写的。详细路径存在于arch/x86/kernel/entry_32.S文件中。
内核栈
内核栈:在Linux中每个进程有两个栈,分别用于用户态和内核态的进程执行(类似于内核页表与用户页表),其中的内核栈就是用于内核态的栈,它和进程的thread_info结构一起放在两个连续的页框大小的空间内。
在kernel 源代码中使用C语言定义了一个联合结构thread_union 方便地表示一个进程的thread_info和内核栈(定义在定义在include/linux/sched.h)
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
结合一个图可以看的更加清楚,其中栈是从高地址向低地址生长的,其中esp寄存器是CPU栈指针,存放内核栈栈顶地址。从用户态刚切换到内核态时,进程的内核栈总是空的(非常类似于进程页表切换到内核态页表,惰性传值),此时esp指向这个栈的顶端。
在x86中调用int指令系统调用后会把用户栈的%esp的值及相关寄存器压入内核栈中,系统调用通过iret指令返回,在返回之前会从内核栈弹出用户栈的%esp和寄存器的状态,然后进行恢复。所以在进入内核态之前要保存进程的上下文,中断结束后恢复进程上下文,那靠的就是内核栈。
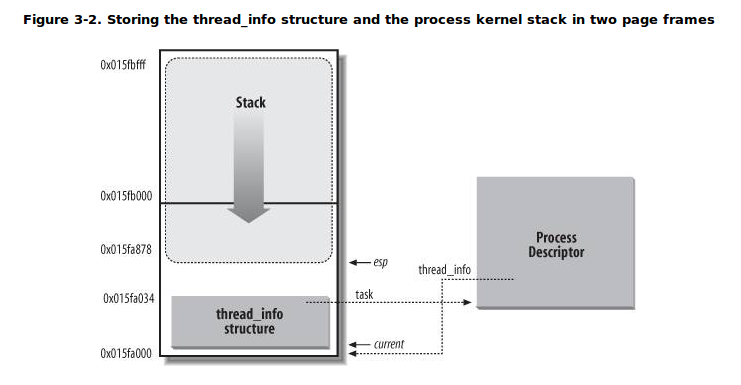
thread_info结构的定义如下
25 struct thread_info {
26 struct task_struct *task; /* main task structure */
27 struct exec_domain *exec_domain; /* execution domain */
28 __u32 flags; /* low level flags */
29 __u32 status; /* thread synchronous flags */
30 __u32 cpu; /* current CPU */
31 int saved_preempt_count;
32 mm_segment_t addr_limit;
33 struct restart_block restart_block;
34 void __user *sysenter_return;
35 #ifdef CONFIG_X86_32
36 unsigned long previous_esp; /* ESP of the previous stack in
37 case of nested (IRQ) stacks
38 */
39 __u8 supervisor_stack[0];
40 #endif
41 unsigned int sig_on_uaccess_error:1;
42 unsigned int uaccess_err:1; /* uaccess failed */
43 };
内核栈保存用户态的esp,eip等寄存器的值,首先得知道内核栈的栈指针,那在进入内核态之前,通过TSS才能获得内核栈的栈指针。
TSS
TSS反映了CPU上的当前进程的特权级。linux为每一个cpu提供一个tss段,并且在tr寄存器中保存该段。在从用户态切换到内核态时,可以通过获取TSS段中的esp0来获取当前进程的内核栈 栈顶指针,从而可以保存用户态的cs,esp,eip等上下文。
注:linux中之所以为每一个cpu提供一个tss段,而不是为每个进程提供一个tss段,主要原因是tr寄存器永远指向它,在任务切换的适合不必切换tr寄存器,而且进程切换的时候只会切换新的esp0。结合scheduler()中的switch_to宏,next_p->thread.esp0装入对应于本地CPU的TSS的esp0字段(其实,任何由sysenter汇编指令产生的从用户态到内核态的特权级转换将把这个地址拷贝到esp寄存器中)。
内核代码中TSS结构的定义位于arch/x86/include/asm/processor.h文件。
其中主要的内容是:
- 硬件状态结构: x86_hw_tss(arch/x86/include/asm/processor.h)
- IO权位图: io_bitmap
- 备用内核栈: stack
linux的tss段中只使用esp0和iomap等字段,并不用它的其他字段来保存寄存器,在一个用户进程被中断进入内核态的时候,从tss中的硬件状态结构中取出esp0(即内核栈栈顶指针),然后切到esp0,其它的寄存器则保存在esp0指的内核栈上而不保存在tss中。
下面,我们看看INIT_TSS定义,其中init_stack是宏定义,指向内核栈 #define init_stack (init_thread_union.stack)
824 #define INIT_TSS { \
825 .x86_tss = { \
826 .sp0 = sizeof(init_stack) + (long)&init_stack, \
827 .ss0 = __KERNEL_DS, \
828 .ss1 = __KERNEL_CS, \
829 .io_bitmap_base = INVALID_IO_BITMAP_OFFSET, \
830 }, \
831 .io_bitmap = { [0 ... IO_BITMAP_LONGS] = ~0 }, \
832 }
内核栈栈顶指针、内核代码段、内核数据段赋值给TSS中的相应项。从而进程从用户态切换到内核态时,可以从TSS段中获取内核栈栈顶指针,进而保存进程上下文到内核栈中。
综上所述:
- 读取tr寄存器,访问TSS段
- 从TSS段中的esp0获取进程内核栈的栈顶指针
- 由控制单元在内核栈中保存当前eflags,cs,ss,eip,esp寄存器的值。
- 由SAVE_ALL保存其寄存器的值到内核栈
- 把内核代码选择符写入CS寄存器,内核栈指针写入ESP寄存器,把内核入口点的线性地址写入EIP寄存器
此时,CPU已经切换到内核态,根据EIP中的值开始执行内核入口点的第一条指令。
参考:
http://guojing.me/linux-kernel-architecture/posts/process-switch/