VFS是管理具体文件系统的接口,Linux可支持数十种文件系统,不同的文件系统可以同时共存于一个系统之中。这些不同类型的文件系统并不是各自封闭的,会进行文件复制和移动等。
VFS是在各种具体的文件系统之上建立了一个抽象层,它屏蔽了不同文件系统间的差异。它之所以可以将各种文件系统纳入其中,是因为它提供了一个通用的文件系统模型。
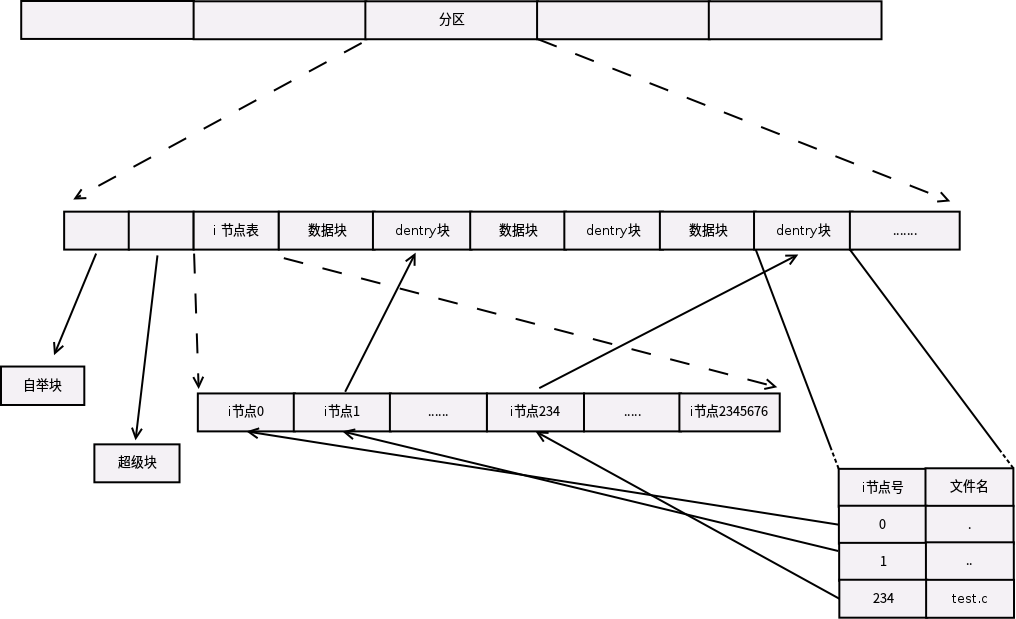
VFS主要通过一组数据结构来描述文件对象。其中有四个基本的结构体:
超级块(struct super_block):它描述一个已安装了的文件系统。
索引结点(struct inode):它描述一个文件。
目录项(strcut dentry):它描述文件系统的层次结构。一个完整路径的每个组成部分都是一个目录项。比如打开/home/lzz/code/hello.c时,内核分别为/,home/,lzz/,code/,hello.c创建相应的目录项。
文件(struct file):它描述一个已被进程打开的文件。
位置:
VFS采用面向对象的思想,在上述每一个结构体中即包含描述每个文件对象属性的数据,又包含对这些数据进行操作的函数指针结构体。也就是说,上述四个基本的结构体中,每一个结构体中又嵌套了一个子结构体,这个子结构体包含了对父结构体进行各种操作的函数指针。
struct dentry (include/linux/dcache.h)
为了方便对目标文件的快速查找,VFS引入了目录项。目标文件路径中的每一项都代表一个目录项,比如/home/test.c中,/,home,test.c都分别是一个目录项。这些目录项都属于路径的一部分,并且每个目录项都与其对应的inode相联系。如果VFS得到了某个dentry,那么也就随之得到了这个目录项所对应文件的inode,这样就可以对这个inode所对应的文件进行相应操作。所以,依次沿着目标文件路径中各部分的目录项进行搜索,最终则可找到目标文件的inode。
与超级块和索引结点不同的是,目录项在磁盘上并没有对应的实体文件,它会在需要时候现场被创建。因此,在目录项结构体中并没有脏数据字段,因为目录项并不会涉及重写到磁盘。
d_inode:与该目录项相关联的索引结点;
struct super_block (include/linux/fs.h)
超级块结构代表一个已经安装了的文件系统,其存储该文件系统的有关信息。对于一个基于磁盘的文件系统来说,这类对象存放于磁盘的特定扇区中;对于非基于磁盘的文件系统,它会在该文件系统的使用现场创建超级块结构并存放在内存中。
s_inode 代表该文件系统中所有的索引结点形成一个双联表,该字段存放这个链表的头结点;
s_files:该文件系统中所有已被打开的文件形成一个双联表,该字段存放这个链表的头结点;
struct file(include/linux/fs.h)
每当一个进程打开一个文件时,内存中有会有相应的file结构体。因此,当一个文件被多个进程打开时,这个文件就会有多个对应的文件结构体。但是,这些文件结构体对应的索引结点和目录项却是唯一的。
struct inode (include/linux/fs.h)
索引结点结构体用来描述存放在磁盘上的文件信息。每当内核对磁盘上的文件进行操作时,就会将该文件的信息填充到一个索引结点可以代表一个普通的文件,也可以代表管道或者设备文件等这样的特殊文件
i_sb_list:每个文件系统中的inode都会形成一个双联表,这个双链表的头结点存放在超级块的s_inodes中。而该字段中的prev和next指针分别指向在双链表中与其相邻的前后两个元素;
i_list:VFS中使用四个链表来管理不同状态的inode结点。inode_unused将当前未使用的inode链接起来,inode_in_use将当前正在被使用的inode链接起来,超级块中的s_dirty将所有脏inode链接起来,i_hash将所有hash值相同的inode链接起来。i_list中包含prev和next两个指针,分别指向与当前inode处于同一个状态链表的前后两个元素。
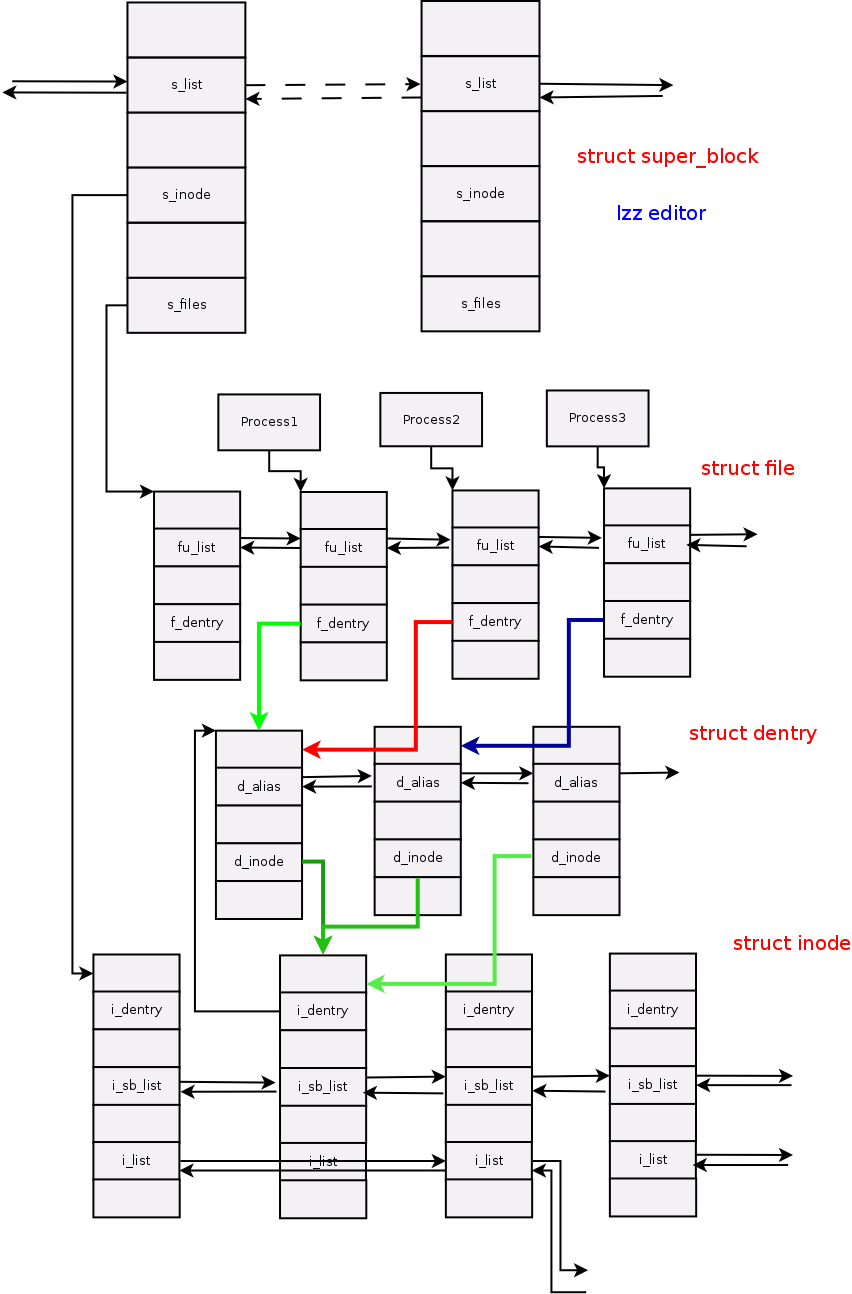
关于此图的说明:
1. 图中平行结构之间的箭头表示这两者之间仍有有若干个类似结点相连接;
PS:在linux 3.14.8 中,从task_struct到struct file有一个过程:
task_struct -> struct files_struct -> struct file -> struct path -> struct dentry
2. 图中阴影部分所示的进程并不是以实际的关系来表示的;
3. 图中彩色线条示意的场景:三个进程分别打开同一个文件。进程1和进程2打开同一路径的文件,因此两者的打开文件对应同一个目录项;而进程3打开的是一个硬链接文件,因此对应的目录项与前两者不同;
4.索引结点中i_sb_list链表是链接一个文件系统中所有inode的链表,因此相邻的inode之间均会由此链表链接;而i_list链接的是处于同一个状态的所有inode。所以,相邻inode之间并不一定链接在一起。