list_head结构那样,等待队列(wait queue)作为linux内核中的基础数据结构,与进程调度紧密结合在一起;在驱动程序中,常常使用等待队列来实现进程的阻塞和进程的唤醒。 数据结构 一般我们的链式线性表都会有一个头结点,以使我们迅速找到这个线性链表的“领导”。在等待队列中,同样有队列头,只不过等待队列头和普通的等待队列结点定义有所不同。
include/linux/wait.h
struct __wait_queue_head {
spinlock_t lock;
struct list_head task_list;
};
typedef struct __wait_queue_head wait_queue_head_t;
可以看到,等待队列头结构中封装了list_head结构。这么做是可以想象到的,因为队列和栈本质上还是双联表。当我们适当限制双联表的某些操作时,就可以实现这样的功能。另外,等待队列头结构中还有一个自旋锁结构的变量lock,它起到了对等待队列进行互斥操作的作用。 在等待队列结构中,除了使用list_head结构外,还有以下几个字段:
typedef struct __wait_queue wait_queue_t;
struct __wait_queue {
unsigned int flags;
#define WQ_FLAG_EXCLUSIVE 0x01
void *private;
wait_queue_func_t func;
struct list_head task_list;
};
flag:指明该等待的进程是互斥还是非互斥,为0时非互斥,为1时互斥; WQ_FLAG_EXCLUSIVE :从变量可以看出,此宏代表进程是互斥的; private:void型指针变量功能强大,你可以赋给它你需要的结构体指针。一般赋值为task_struct类型的指针,也就是说指向一个进程; func:函数指针,指向该等待队列项的唤醒函数; 我们可以通过下述图来详细了解等待队列头和等待队列的结构关系: 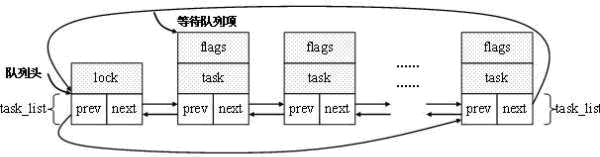 1.定义及初始化 对于结构的初始化 内核中使用init_waitqueue_head宏来初始化等待队列头。
1.定义及初始化 对于结构的初始化 内核中使用init_waitqueue_head宏来初始化等待队列头。
include/linux/wait.h
#define init_waitqueue_head(q) \
do { \
static struct lock_class_key __key; \
\
__init_waitqueue_head((q), &__key); \
} while (0)
事实上,这个do-while循环语句只会执行一次。那么,为什么要选择使用这个循环语句?在定义宏的时候将上述语句嵌套在一个大括号里也可以啊!可能我们如下那样使用一个宏:
if(conditon)
init_waitqueue_head(q);
else
do_somthing_else();
如果我们去除do-while,那么替换后会编译错误。 在init_waitqueue_head宏中调用的__init_waitqueue_head函数定义如下:
void __init_waitqueue_head(wait_queue_head_t *q, struct lock_class_key *key)
{
spin_lock_init(&q->lock);
lockdep_set_class(&q->lock, key);
INIT_LIST_HEAD(&q->task_list);
}
在这个函数中,首先利用自旋锁初始化函数初始化这个自旋锁;在上述等待队列头的定义中,我们可以看到task_list字段是一个list_head结构类型,因此我们使用INIT_LIST_HEAD对这个链表进行初始化。这些过程都是我们所熟悉的。 对于初始化的一些函数与宏,我们可以查看代码即可。包括添加/移除等待队列 例如:add_wait_queue添加函数将等待队列wait添加到以q为等待队列头的那个等待队列链表中。
22void add_wait_queue(wait_queue_head_t *q, wait_queue_t *wait)
23{
24 unsigned long flags;
25
26 wait->flags &= ~WQ_FLAG_EXCLUSIVE;
27 spin_lock_irqsave(&q->lock, flags);
28 __add_wait_queue(q, wait);
29 spin_unlock_irqrestore(&q->lock, flags);
30}
我们可以看到flags的结果必然是0,也就是说这个函数是将非互斥进程添加到等待队列当中。而且在调用具体的添加函数时候,使用关中断并保护现场的自旋锁方式使得添加操作每次只被一个进程访问。 具体的添加过程是将当前进程所对应的等待队列结点wait添加到等待队列头结点q之后。具体来说,就是将new->task_list结点添加到以head->task_list为头指针的双链表当中。另外,通过add_wait_queue_exclusive函数可以将一个互斥进程添加到等待队列当中。从添加过程可以发现,add_wait_queue函数会将非互斥进程添加到等待队列的前部。
122static inline void __add_wait_queue(wait_queue_head_t *head, wait_queue_t *new)
123{
124 list_add(&new->task_list, &head->task_list);
125}
另外, add_wait_queue_exclusive添加函数则会将互斥进程添加到等待队列的末尾。
33void add_wait_queue_exclusive(wait_queue_head_t *q, wait_queue_t *wait)
34{
35 unsigned long flags;
36
37 wait->flags |= WQ_FLAG_EXCLUSIVE;
38 spin_lock_irqsave(&q->lock, flags);
39 __add_wait_queue_tail(q, wait);
40 spin_unlock_irqrestore(&q->lock, flags);
41}
remove_wait_queue函数用于将等待队列项wait从以q为等待队列头的等待队列中移除,源码如下。
44void remove_wait_queue(wait_queue_head_t *q, wait_queue_t *wait)
45{
46 unsigned long flags;
47
48 spin_lock_irqsave(&q->lock, flags);
49 __remove_wait_queue(q, wait);
50 spin_unlock_irqrestore(&q->lock, flags);
51}
150static inline void __remove_wait_queue(wait_queue_head_t *head,
151 wait_queue_t *old)
152{
153 list_del(&old->task_list);
154}
有了上述的基础,那么移除函数就简单了许多。
这里我们重点说一下在等待队列上睡眠
实现进程阻塞大致过程就是将当前进程的状态设置成睡眠状态,然后将这个进程加入到等待队列即可。在linux内核中有一组函数接口来实现这个功能。
4313void __sched interruptible_sleep_on(wait_queue_head_t *q)
4314{
4315 sleep_on_common(q, TASK_INTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
4316}
4317EXPORT_SYMBOL(interruptible_sleep_on);
4318
4319long __sched
4320interruptible_sleep_on_timeout(wait_queue_head_t *q, long timeout)
4321{
4322 return sleep_on_common(q, TASK_INTERRUPTIBLE, timeout);
4323}
4324EXPORT_SYMBOL(interruptible_sleep_on_timeout);
4325
4326void __sched sleep_on(wait_queue_head_t *q)
4327{
4328 sleep_on_common(q, TASK_UNINTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
4329}
4330EXPORT_SYMBOL(sleep_on);
4331
4332long __sched sleep_on_timeout(wait_queue_head_t *q, long timeout)
4333{
4334 return sleep_on_common(q, TASK_UNINTERRUPTIBLE, timeout);
4335}
4336EXPORT_SYMBOL(sleep_on_timeout);
通过上述源码,你可以发现这些函数在内部都调用了sleep_on_common函数,通过传递不同的值来实现不同的功能。而这个通用函数的三个参数分别关注的是:进程要加入到那个等待队列?进程是那种睡眠状态(TASK_UNINTERRUPTIBLE还是TASK_INTERRUPTIBLE)?进程睡眠的时间?
4292static long __sched
4293sleep_on_common(wait_queue_head_t *q, int state, long timeout)
4294{
4295 unsigned long flags;
4296 wait_queue_t wait;
4297
4298 init_waitqueue_entry(&wait, current);
4299
4300 __set_current_state(state);
4301
4302 spin_lock_irqsave(&q->lock, flags);
4303 __add_wait_queue(q, &wait);
4304 spin_unlock(&q->lock);
4305 timeout = schedule_timeout(timeout);
4306 spin_lock_irq(&q->lock);
4307 __remove_wait_queue(q, &wait);
4308 spin_unlock_irqrestore(&q->lock, flags);
4309
4310 return timeout;
4311}
在此函数中,首先定义了一个等待队列项结点,通过 init_waitqueue_entry函数对其进行初始化。可以从下述初始化源码中看到,此时该等待队列项指向当前当前进程。而唤醒函数指针func则指向内核自定义的一个默认唤醒函数default_wake_function。
98static inline void init_waitqueue_entry(wait_queue_t *q, struct task_struct *p)
99{
100 q->flags = 0;
101 q->private = p;
102 q->func = default_wake_function;
103}
初始化完毕后,通过__set_current_state函数将当前进程的状态设置成state。接着,在自旋锁的保护下,将当前进程对应的等待队列结点插入到等待队列链表当中。更重要的是,在schedule_timeout函数中不仅要设置进程的睡眠时间(以jiffies为单位的),还要使用schedule函数进行重新调度。一旦使用了schedule函数后,也就意味这当前这个进程真正的睡眠了,那么接下来的代码会在它唤醒后执行。当该进程被唤醒后(资源可用时),会从等待队列中将自己对应的那个等待队列结点wait移除。 上述过程都是在自旋锁保护下进行的,并且在整个执行过程中不可被其他中断所打断。现在再回过头去看一开始的那四个睡眠函数接口,你就明白了它们各自的不同之处了。
5.唤醒函数
唤醒函数会唤醒以x为头结点的等待队列中的等待队列项所对应的进程。与睡眠函数类似,内核中也有一组函数可以对阻塞的进程进行唤醒。
170#define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL)
171#define wake_up_nr(x, nr) __wake_up(x, TASK_NORMAL, nr, NULL)
172#define wake_up_all(x) __wake_up(x, TASK_NORMAL, 0, NULL)
175#define wake_up_interruptible(x) __wake_up(x, TASK_INTERRUPTIBLE, 1, NULL)
176#define wake_up_interruptible_nr(x, nr) __wake_up(x, TASK_INTERRUPTIBLE, nr, NULL)
177#define wake_up_interruptible_all(x) __wake_up(x, TASK_INTERRUPTIBLE, 0, NULL)
通过上述代码,我们可以发现这些唤醒函数均调用了__wake_up函数。__wake_up函数的四个参数分别指:头结点指针、唤醒进程的类型、唤醒进程的数量和一个附加的void型指针变量。
3999void __wake_up(wait_queue_head_t *q, unsigned int mode,
4000 int nr_exclusive, void *key)
4001{
4002 unsigned long flags;
4003
4004 spin_lock_irqsave(&q->lock, flags);
4005 __wake_up_common(q, mode, nr_exclusive, 0, key);
4006 spin_unlock_irqrestore(&q->lock, flags);
4007}
在__wake_up函数又通过传递不同的参数调用__wake_up_common函数来实现不同的唤醒功能。
3975static void __wake_up_common(wait_queue_head_t *q, unsigned int mode,
3976 int nr_exclusive, int wake_flags, void *key)
3977{
3978 wait_queue_t *curr, *next;
3979
3980 list_for_each_entry_safe(curr, next, &q->task_list, task_list) {
3981 unsigned flags = curr->flags;
3982
3983 if (curr->func(curr, mode, wake_flags, key) &&
3984 (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
3985 break;
3986 }
3987}
list_for_each_entry_safe函数将遍历整个等待队列中的链表,通过每次的逻辑判断来唤醒相应的进程。
这个if语句初看起来有点麻烦,不过我们一点一点的将它拆解。 curr->func(curr, mode, sync, key):即执行默认的唤醒函数,将指定的进程curr以mode方式唤醒。成功唤醒返回1;否则,返回0; (flags & WQ_FLAG_EXCLUSIVE):判断当前进程是否以互斥形式唤醒。
是互斥形式则返回1;否则返回0; !–nr_exclusive:nr_exclusive为需要唤醒的互斥进程的数量。 这三个部分是通过逻辑与连接起来的。根据逻辑与的运算规则,只有当第一部分为真时才会判断第二部分的值,依次再判断第三部分的值。 通过上述的等待队列的添加过程我们知道,
等待队列中前面均是非互斥进程,后面才是互斥进程。因此,唤醒函数总先唤醒全部的非互斥进程。因为当__wake_up_commom函数每一次去判断if语时,总会“不自觉”去执行默认的唤醒函数(除非唤醒失败,那么会退出遍历宏);当全部的非互斥进程被唤醒后,第二个判断条件也就成立了。因此__wake_up_commom函数会依次唤醒nr_exclusive个互斥进程;当–nr_exclusive为0时(!–nr_exclusive也就为真),整个遍历过程也恰好结束,而此时if语句的三个判断条件才刚好满足(这段代码太强大了!!!)。
关于条件睡眠,虽然函数实现与睡眠函数不同,但是基本思想是相似的,可以查找相应的源码进行分析。