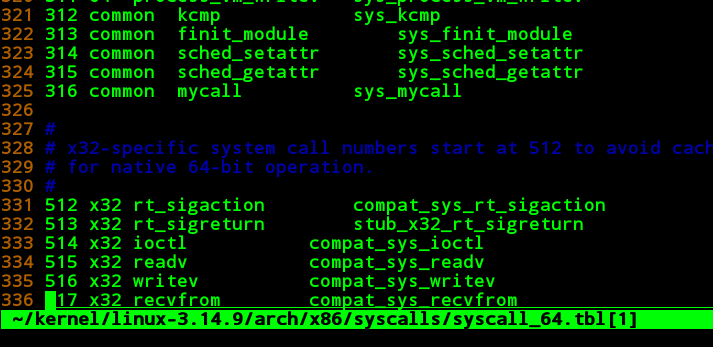
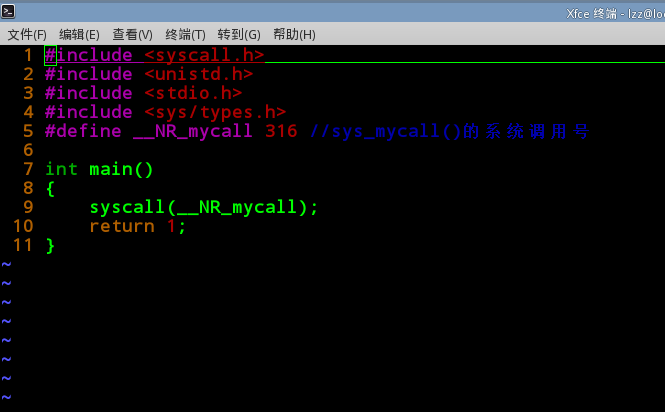
page-types.c这个代码位于kernel源码下的tool/vm/page-type.c
我们可以通过使用makefile编译这个程序,通过这个程序我们可以查找每个特定进程的page frame number 记住这个pfn只是一个index而已,我们如果想取得真实的物理地址需要使用pfn*page_size,当然这个是page frame 的物理起始地址。
这个程序是位于用户态,通过查找/proc/pid/pagemap 和 /proc/pid/maps来找到pfn的。
这个程序的功能比较强大,我们使用的仅仅是指定一个$./page-type -p pid
首先mian()中先要解析参数,然后通过parse_number()来获取用户输入的pid,然后我们知道当指定了一个pid,也就意味着我们打开一个正在运行的pid的maps
[root@localhost 13352]# ls attr clear_refs cpuset fd limits mountinfo ns oom_score_adj root stack syscall autogroup cmdline cwd fdinfo loginuid mounts numa_maps pagemap sched stat task auxv comm environ gid_map maps mountstats oom_adj personality sessionid statm uid_map cgroup coredump_filter exe io mem net oom_score projid_map smaps status wchan
00400000-00401000 r-xp 00000000 fd:02 4330673 /home/lzz/mca-ras/src/tools/simple_process/simple_process 00600000-00601000 r--p 00000000 fd:02 4330673 /home/lzz/mca-ras/src/tools/simple_process/simple_process 00601000-00602000 rw-p 00001000 fd:02 4330673 /home/lzz/mca-ras/src/tools/simple_process/simple_process 019b8000-019d9000 rw-p 00000000 00:00 0 [heap] 33c1a00000-33c1a20000 r-xp 00000000 fd:01 2622088 /usr/lib64/ld-2.18.so 33c1c1f000-33c1c20000 r--p 0001f000 fd:01 2622088 /usr/lib64/ld-2.18.so 33c1c20000-33c1c21000 rw-p 00020000 fd:01 2622088 /usr/lib64/ld-2.18.so 33c1c21000-33c1c22000 rw-p 00000000 00:00 0 33c1e00000-33c1fb4000 r-xp 00000000 fd:01 2622743 /usr/lib64/libc-2.18.so 33c1fb4000-33c21b3000 ---p 001b4000 fd:01 2622743 /usr/lib64/libc-2.18.so 33c21b3000-33c21b7000 r--p 001b3000 fd:01 2622743 /usr/lib64/libc-2.18.so 33c21b7000-33c21b9000 rw-p 001b7000 fd:01 2622743 /usr/lib64/libc-2.18.so 33c21b9000-33c21be000 rw-p 00000000 00:00 0 7f3fe081a000-7f3fe081d000 rw-p 00000000 00:00 0 7f3fe083c000-7f3fe083e000 rw-p 00000000 00:00 0 7fff87571000-7fff87592000 rw-p 00000000 00:00 0 [stack] 7fff875fe000-7fff87600000 r-xp 00000000 00:00 0 [vdso] ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
我们可以看到这个进程每个段,包括BSS CODE HEAP STACK等。然后哦page-types.c中的parse_pid读取这个表里面的信息。
关于这个表每个列的含义看这个http://stackoverflow.com/questions/1401359/understanding-linux-proc-id-maps
我们主要关注头两行,vm_start vm_end。这时我们要获取虚拟地址的page number:
pg_start[nr_vmas] = vm_start / page_size; pg_end[nr_vmas] = vm_end / page_size;
至于这个page_size可以通过page_size = getpagesize();获取。这里我们要注意unsigned long的取值范围是0-2^64-1,-1也就是2^64-1
然后我们进入walk_task()函数,因为process可能会存在匿名映射,所以我们需要使用filebacked_path[i]判断文件地址。
进入walk_vma()后。
这时我们需要读取/proc/pid/pagemap,这个我们用常规打不开,所以我们只好通过vm index读取的方式获得pages和pfn的相关信息。
详细我们查看
http://stackoverflow.com/questions/17021214/decode-proc-pid-pagemap-entry
https://www.kernel.org/doc/Documentation/vm/pagemap.txt
关注
* Bits 0-54 page frame number (PFN) if present
* Bit 63 page present
下面就是通过编程的方式获取这个的0-54位。总的来所就是使用位操作:
#define PFN_MASK (((1LL)<<55)-1) //意味着0-54位都为1 *phy=(buf&PFN_MASK)*page_size+vir%page_size
核心函数:
for (i = 0; i < pages; i++) {
// printf("%lx\n",buf[i]);
pfn = pagemap_pfn(buf[i]);
if (pfn) {
printf("%lx", pfn);
printf("\t0x%lx",pfn*page_size);
walk_pfn(index + i, pfn, 1, buf[i]);
}
}
我们可以看到pfn只是一个index而已,真正的物理地址需要pfn*page_size的方式,后面的各种属性是通过读取/proc/kpageflags获得。结果如下:
/home/lzz/mca-ras/src/tools/simple_process/simple_process 93a12 0x93a12000 referenced,uptodate,lru,active,mmap,private /home/lzz/mca-ras/src/tools/simple_process/simple_process 54d07 0x54d07000 uptodate,lru,active,mmap,anonymous,swapbacked /home/lzz/mca-ras/src/tools/simple_process/simple_process 9aa43 0x9aa43000 uptodate,lru,active,mmap,anonymous,swapbacked [heap] 91f74 0x91f74000 uptodate,lru,active,mmap,anonymous,swapbacked 60fb3 0x60fb3000 uptodate,lru,active,mmap,anonymous,swapbacked ...............