最近在使用Keras对我定义的目标进行训练和目标检测,目前最火的目标检测框架就是Faster RCNN了,Faster RCNN克服了他的前辈RCNN和Fast RCNN固有的一些问题,提升了检测速度,使得在视频领域的目标检测成为可能。
RCNN算法这里简单提一下:
- 区域提名:通过Selective Search从原始图片提取2000个左右区域候选框;
- 区域大小归一化:把所有侯选框缩放成固定大小(原文采用227×227);
- 特征提取:通过CNN网络,提取特征;
- 分类与回归:在特征层的基础上添加两个全连接层,再用SVM分类来做识别,用线性回归来微调边框位置与大小,其中每个类别单独训练一个边框回归器。
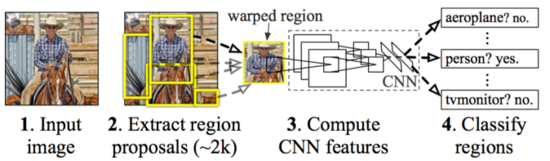
RCNN最大弊端就是拥有太多的候选框,这个导致每个候选框都要分别通过CNN提取特征,计算量依然很大,其中有不少其实是重复计算,最终这个也使得目标识别非常慢。
Fast RCNN是RCNN的改进版,借鉴了SPP-Net中对于提取到的卷积层特征的处理,即提出去掉了原始图像上对于ROI区域的crop/warp等操作(也就是把所有的候选框都做归一化),换成了在提取到的卷积特征上的空间金字塔池化层(Spatial Pyramid Pooling,SPP)。因此无论图片大小如何,无论图像向量唯独如何,经过Spatial Pyramid Pooling操作,提取出来的提取出来的维度数据都是一致的,这样就可以统一送至全连接层了。

ROI操作(Spatial Pyramid Pooling,SPP):
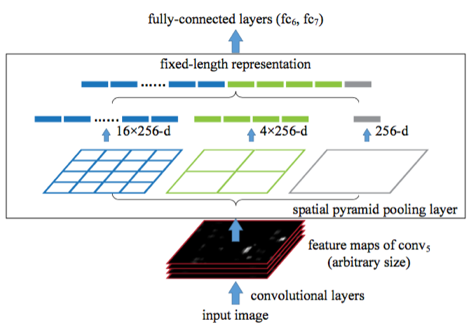
通过上图可以看到feature map 经过SPP层被分割成了16个256d+4个256d+1个256d的ROI 特征向量。因此在Fast RCNN中输入的候选框可大可小,然后根据得到的候选框区域投影到整幅图片的特征向量层。
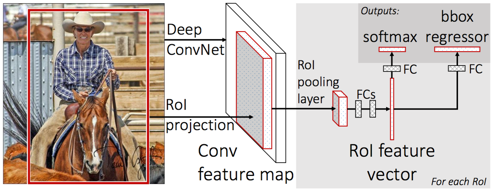
总的Fast RCNN步骤如下:
- 特征提取:以整张图片为输入利用CNN得到图片的特征层;
- 区域提名:通过Selective Search等方法从原始图片提取区域候选框,并把这些候选框一一投影到最后的特征层;
- 区域归一化:针对特征层上的每个区域候选框进行RoI Pooling操作,得到固定大小的特征表示;
- 分类与回归:然后再通过两个全连接层,分别用softmax多分类做目标识别,用回归模型进行边框位置与大小微调。
Faster RCNN在Fast RCNN的基础上更进一部,不再使用Selective Search等方法获取候选框,而是利用RPN(Region Proposal Networks)网络来计算候选框。RPN以一张任意大小的图片为输入,输出一批矩形区域提名,每个区域对应一个目标分数和位置信息。当然RPN和Fast RCNN共用基础的图片特征。
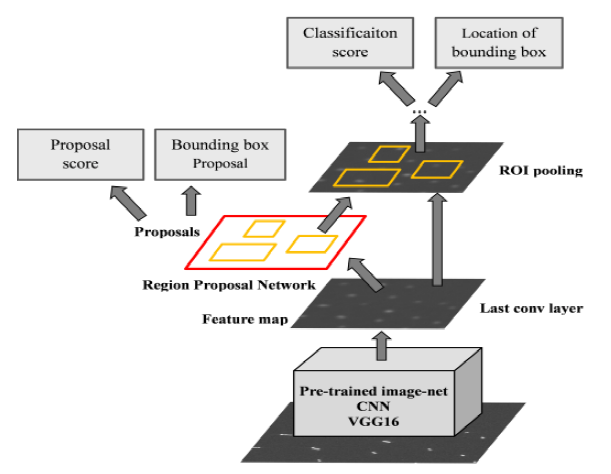
RPN会产生K个Anchor Box,而每个Anchor Box都包括2K个score和4K个坐标点,socre就是这个区域的评分,有多大概率是这个东西?4K就是矩形的是个坐标位置。然后将这些Anchor Box和整幅图的特征向量结合起来(就是Feature Map ——> ROI Feature的操作,就是上面Fast RCNN步骤三,最后产生固定大小的特征表示),得到的固定大小的特征表示可以进行对应区域的classification,分类这个区域是不是那个物体,然后用 k 个回归模型(各自对应不同的Anchor Box)微调候选框位置与大小,最后进行目标真正的分类,判断这个目标是什么东西。
总的步骤:
- 特征提取:同Fast R-CNN,以整张图片为输入,利用CNN得到图片的特征层;
- 区域提名:在最终的卷积特征层上利用 k 个不同的矩形框(Anchor Box)进行提名, k 一般取9;
- 分类与回归:对每个Anchor Box对应的区域进行object/non-object二分类,并用 k 个回归模型(各自对应不同的Anchor Box)微调候选框位置与大小,最后进行目标分类。
Faster RCNN得到区域提名以后,后续操作和Fast RCNN一模一样!事实上只需关注RPN即可,如下图流程(忽略前后的不同….):

梳理了整个算法脉络大白话就是:目标检测分为两大部分:1)区域提名 2)特征回归分类。每个部分都是各大算法进化过来的。
参考文献
[1] R. Girshick, J. Donahue, T. Darrell, J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. ImageNet Large-Scale Visual Recognition Challenge workshop, ICCV, 2013.
[2] R. Girshick, J. Donahue, T. Darrell, J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
[3] R. Girshick, J. Donahue, T. Darrell, J. Malik. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, May. 2015.
[4] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV. 2014.
[5] S. Ren, K. He, R. Girshick, J. Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Advances in Neural Information Processing Systems 28 (NIPS), 2015.