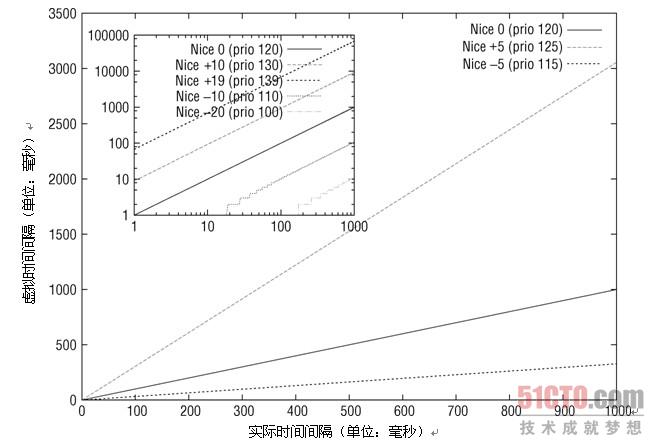
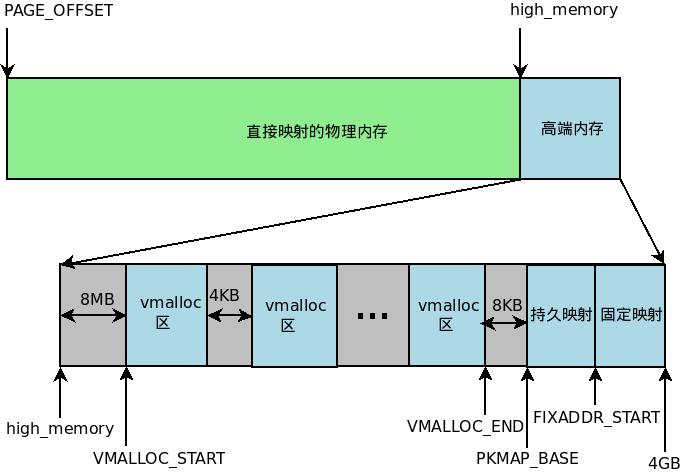
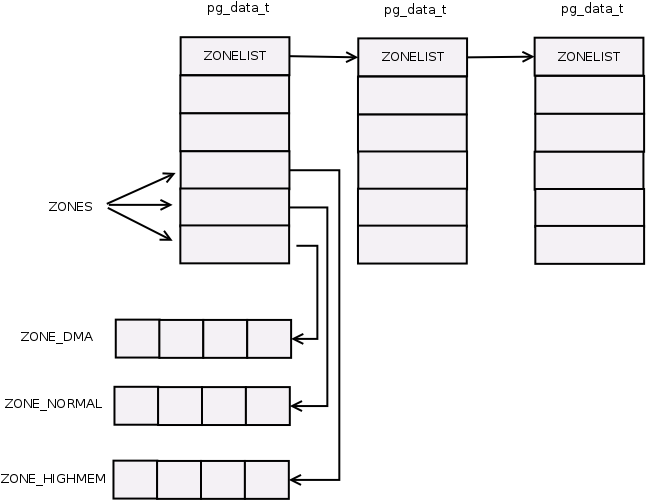
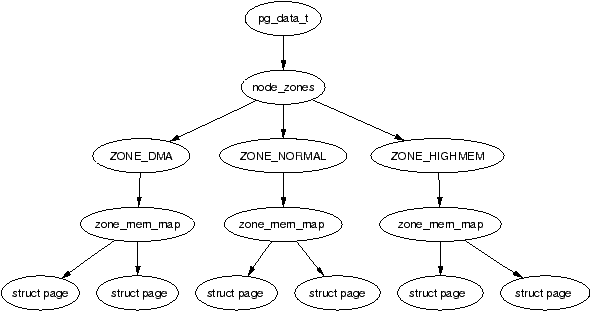
伙伴系统(buddy system)在物理内存管理中占有重要地位。
我们知道物理内存被分为三大部分:DMA、NORMAL、HIGHMEN三个区域。每个内存域都有一个struct zone的实例。而这个struct zone 的实例又被struct pglist_data管理。具体看http://www.lizhaozhong.info/archives/1184
page frame <==> struct page
struct zone 这个结构体非常庞大,总的来说分成三部分,每一部分由 ZONE_PADDING(_pad1_)这种标示分割。我们可以通过struct zone 下的unsigned long zone_start_pfn 找到某个特定的page!但是这种page frame,我们无法知道空闲页框的布局,不利于分配page frame。
具体zone定义:http://lxr.free-electrons.com/source/include/linux/mmzone.h#L327
为了尽量分配连续的page frame,避免外部碎片的产生,伙伴系统(buddy system)满足这个需求。
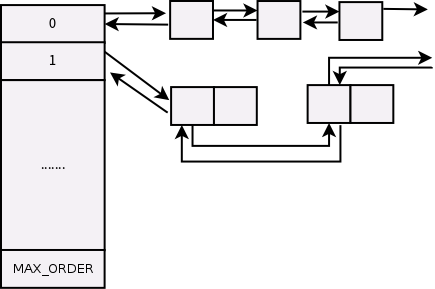
每个内存域(struct zone)的实例都有free_area数组,这个数组大小是11,也就是说空闲区域有0-10阶的page frame 块链表。比如free_area[3]所对应的页框块链表中,每个节点对应8个连续的页框(2的3次方)。
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
#else
#define MAX_ORDER CONFIG_FORCE_MAX_ZONEORDER
#endif
struct zone{
........
476 ZONE_PADDING(_pad1_)
477
478 /* Write-intensive fields used from the page allocator */
479 spinlock_t lock;
480
481 /* free areas of different sizes */
482 struct free_area free_area[MAX_ORDER];
483
484 /* zone flags, see below */
485 unsigned long flags;
486
487 ZONE_PADDING(_pad2_)
......
}
而struct free_area如下http://lxr.free-electrons.com/source/include/linux/mmzone.h#L92
92 struct free_area {
93 struct list_head free_list[MIGRATE_TYPES];
94 unsigned long nr_free;
95 };
通过声明看到free_list是一个链表数组。nr_free表示当前链表中空闲页框块的数目,比如free_area[3]中nr_free的值为5,表示有5个大小为8的页框块,那么总的页框数目为40。
具体概述上面buddy system结构就是:
在/proc中我们可以查看到每个阶空闲大小的PFN数量(注:本机使用的是AMD64系统,在AMD64中没有ZONE_HIGHMEN,ZONE_DMA寻值为16M,ZONE_DMA32寻值为0-4GiB,在32为机器上DMA32为0)
[root@localhost cgroup_unified]# cat /proc/buddyinfo Node 0, zone DMA 8 7 6 5 4 2 1 2 2 3 0 Node 0, zone DMA32 1059 1278 9282 1868 1611 260 52 20 7 2 1
在struct list_head free_list[MIGRATE_TYPES]中,我们发现每个阶都带有一个MIGRATE_TYPES标志,通过这种方式,系统又把每个阶的空闲page更加详细的分割,具体类型有不可移动,移动,保留等。
38 #define MIGRATE_UNMOVABLE 0 39 #define MIGRATE_RECLAIMABLE 1 40 #define MIGRATE_MOVABLE 2 41 #define MIGRATE_PCPTYPES 3 /* the number of types on the pcp lists */ 42 #define MIGRATE_RESERVE 3 43 #define MIGRATE_ISOLATE 4 /* can't allocate from here */ 44 #define MIGRATE_TYPES 5
这是为了更大限度的满足连续物理页框的需要,如果要分配一种MIGRATE_UNMOVABLE类型的页框,而两边的页框是可以移动的,这样就限制了连续大页框的分配,产生了外部碎片。
使用MIGRATE_TYPES策略后,不可移动的页面的不可移动性仅仅影响它自身的类别而不会导致一个不可移动的页面两边都是可移动的页面。这就是MIGRATE_TYPE被引入的目的。
MIGRATE_TYPE限制了内存页面的分配地点从而避免碎片,而不再仅仅寄希望于它们被释放时通过合并避免碎片[1]。
这种策略在proc中也可以查看:
[root@localhost cgroup_unified]# cat /proc/pagetypeinfo Page block order: 9 Pages per block: 512 Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10 Node 0, zone DMA, type Unmovable 1 4 4 1 1 1 1 1 0 0 0 Node 0, zone DMA, type Reclaimable 5 1 1 0 0 0 0 1 1 1 0 Node 0, zone DMA, type Movable 2 0 2 4 3 1 0 0 1 1 0 Node 0, zone DMA, type Reserve 0 0 0 0 0 0 0 0 0 1 0 Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Node 0, zone DMA32, type Unmovable 1 0 8 1 17 15 5 0 0 0 0 Node 0, zone DMA32, type Reclaimable 1041 162 1 0 1 1 1 1 1 0 0 Node 0, zone DMA32, type Movable 698 78 7 1221 1194 232 45 20 6 0 0 Node 0, zone DMA32, type Reserve 0 0 0 0 0 0 0 0 0 1 1 Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0 Number of blocks type Unmovable Reclaimable Movable Reserve Isolate Node 0, zone DMA 1 2 4 1 0 Node 0, zone DMA32 89 93 1216 2 0
参考: