kernel中包含着庞大的元数据struct page,一个struct page管理一个4k大小的物理内存(默认),之前我们进行的是从task_struct向vm_area_struct一直到最后的struct page的寻找过程。
但是从RAS角度,如果一个page发生问题,那么如何从struct page向上找到对应的page table呢(找到page table也就找到了pid、task_struct….)?这时候就要使用逆向映射。
为了尽可能减小strut page的大小,Andrea复用了page的struct address_space *mapping数据结构来表示不同类型的页,主要分为三个类型swap、page cache、anonymous page。这里我们只说明page cache 与 anonymous page的逆向映射。
0.什么是匿名页?
想说明匿名页,必须首先说明什么是映射页。在用户态下打开一个文件,kernel会使用map() 映射文件的某个部分,这个部分在用户态地址空间存在地址,这种页要被回收的时候,会检查是否是dirty,如果为dirty,则需要写回相应的磁盘文件。
而匿名页没有对应了打开的磁盘文件,比如进程的用户态堆和stack可以称为匿名页,当匿名页过长时间驻留内存时,kernel可以要把它保存到一个特定的磁盘分区,这就是swap分区!
首先我们看一下struct page的结构:
struct page {
/* First double word block */
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
union {
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
void *s_mem; /* slab first object */
};
/* Second double word */
struct {
union {
pgoff_t index; /* Our offset within mapping. */
....
struct address_space *mapping是确定页是映射还是匿名
- mapping为空表示该页属于交换高速缓存swap;
- mapping非空,且最低位是1,表示该页为匿名页,同时mapping字段中存放的是指向anon_vma描述符的指针;
- mapping非空,且最低位是0,表示该页为映射页;同时mapping字段指向对应文件的address_space对象。
而第二部分的pgoff_t index是用来指明偏移量的,在映射页中是以页为单位偏移。
1.当我们判断这个页是映射页时,每个page的mapping都指向一个对应的address_space,这个结构是page cache的核心,可以通过这个找到具体的inode!
2.当我们判断这个页是匿名页时,那么这个page指向struct anon_vma
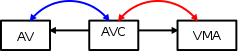
但是这里kernel在2010年提交过一个补丁,为了解决大量fork出来的子进程占用大量anon_vma结构,他们的结构完全相同,而且这种结构导致匿名映射寻找也是O(N)的复杂度。所以引入了struct anon_vma_chain
假设系统只有一个task_struct时,组织结构如下:
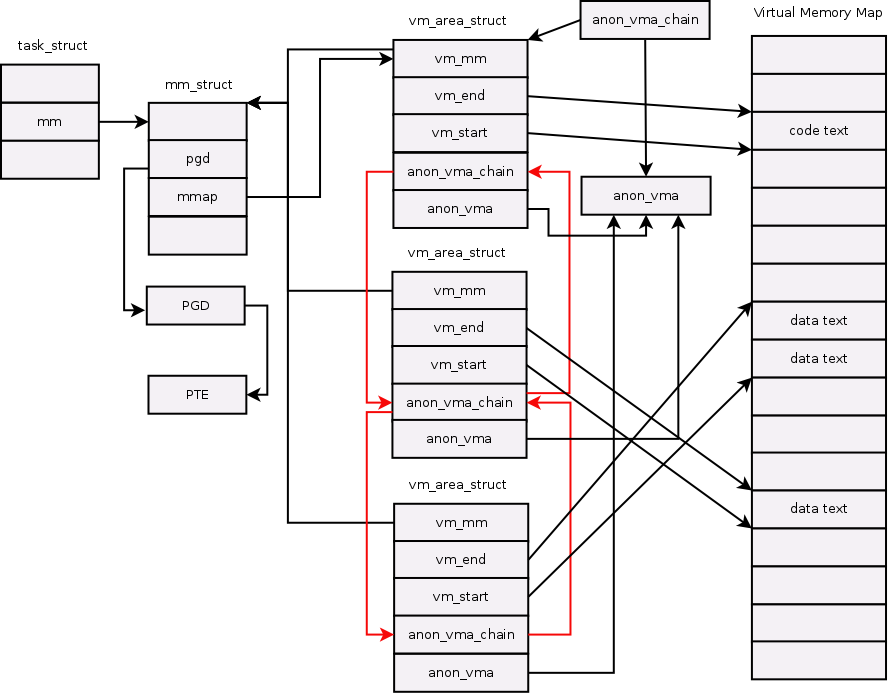
struct anon_vma_chain {
struct vm_area_struct *vma;
struct anon_vma *anon_vma;
struct list_head same_vma; /* locked by mmap_sem & page_table_lock */
struct rb_node rb; /* locked by anon_vma->rwsem */
unsigned long rb_subtree_last;
#ifdef CONFIG_DEBUG_VM_RB
unsigned long cached_vma_start, cached_vma_last;
#endif
};
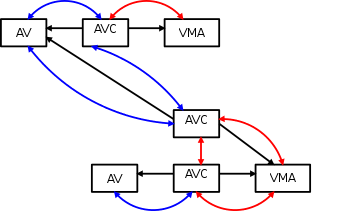
这样子就形成了anon_vma与vm_area_struct N对N的组织形式,当父进程fork出一个子进程,那么这个子进程拥有一个vm_area_struct,当然也就拥有一个anon_vma,除非发生COW,否则父子进程共享vm_area_struct。
this patch changes the way anon_vmas and VMAs are linked, which allows us to associate multiple anon_vmas with a VMA. At fork time, each child process gets its own anon_vmas, in which its COWed pages will be instantiated. The parents’ anon_vma is also linked to the VMA, because non-COWed pages could be present in any of the children.
3.刚才说的是正向的一个匿名页查找,现在我们反过来,一直一个struct page,找到这个匿名页的page table。结合正向的结构图与相关struct成员,我们可以画出相应的结构图,这里page指向anon_vma就是通过mapping做到的:
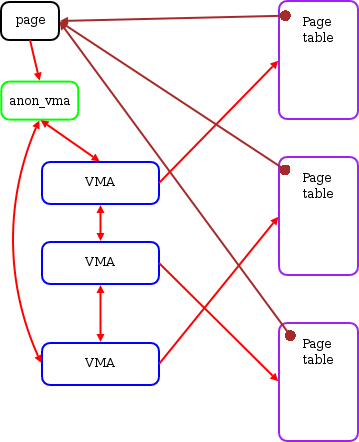
而anon_vma (AV),anon_vma_chain entry (AVC),vm_area_struct(VMA)三者的关系如下
当father process fork()出来子进程后,会产生新的struct anon_vma ,这个结构就会分裂,创建VMA->创建AVC->创建AV。
参考: