综述 http://www.lizhaozhong.info/archives/690
之前我们在编写模块时候,对内核地址空间有一个粗略的了解,最近结合内存管理代码的学习,使得我对内核中内存管理有了更清晰的认识!
首先我们看一下http://www.lizhaozhong.info/archives/1003
这个图对kernel中kmalloc、vmalloc有比较详细的说明。
下面我们阐述一下Linux 物理内存管理
在内核中,内核认为一旦有内核函数申请内存,那么就必须立刻满足该申请内存的请求,并且这个请求一定是正确合理的。相反,对于用户态申请内存的请求,内核总是尽量延后分配物理内存,用户进程总是先获得一个虚拟内存区的使用权,最终通过缺页异常获得一块真正的物理内存。
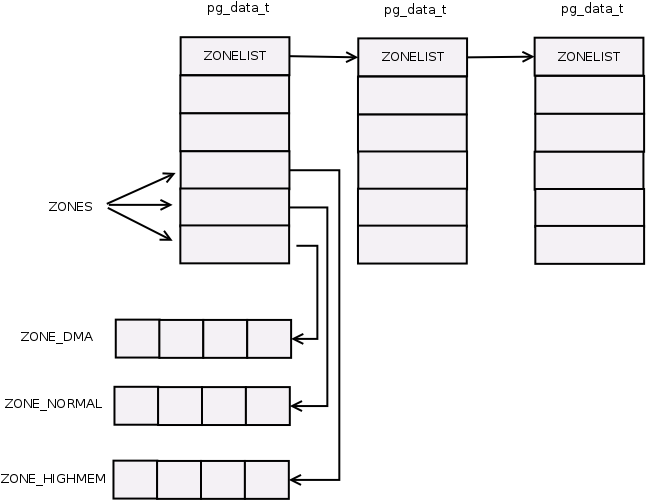
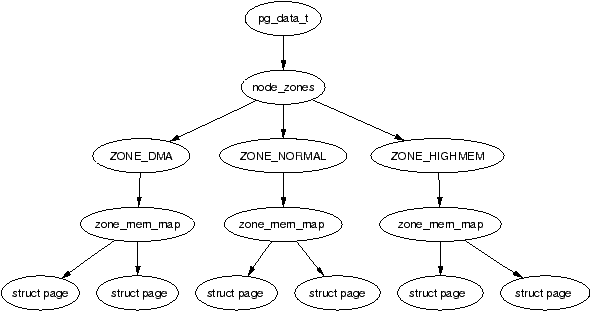
我们之前通过代码看到,linux将内核分为三个区域DMA,NORMAL,HIGHMEM
我们要明白的是只是针对内核有这三个区域,用户空间没有!
这三个区域与体系结构相关,比如有的DMA所占用的物理内存区域是0-16M,有的是0-4GB。这个我们要结合具体的体系结构来看。
从物理内存布局来说DMA 0~16M NORMAL 16M~896M HIGHMEM 大于896MB
我们拿IA32举例:
kernel可以直接将低于896MB大小的物理内存(即ZONE_DMA,ZONE_NORMAL)映射到内核地址空间,但超出896MB大小的page frame 并不映射在内核线性地址空间的第4个GB。
1.高端内存不能全部映射到内核空间,也就是说这些物理内存没有对应的线性地址。内核此时可以使用alloc_pages()和alloc_page()来分配高端内存,因为这些函数返回页框描述符的线性地址。
2.内核地址空间的后128MB专门用于映射高端内存,否则,没有线性地址的高端内存不能被内核所访问。这些高端内存的内核映射显然是暂时映射的,否则也只能映射128MB的高端内存。当内核需要访问高端内存时就临时在这个区域进行地址映射,使用完毕之后再用来进行其他高端内存的映射。
The lower 896 MB, from 0xC0000000 to 0xF7FFFFFF, is directly mapped to the kernel physical address space, and the remaining 128 MB, from 0xF8000000 to 0xFFFFFFFF, is used on demand by the kernel to be mapped to high memory. When inuser mode, translations are only effective for the first region, thus protecting the kernel from user programs, but when in kernel mode, translations are effective for both regions, thus giving the kernel an easy way to refer to the buffers of processes—it just uses the process’ own mappings.[1]
由于要进行高端内存的内核映射,因此直接能够映射的物理内存大小只有896MB,该值保存在high_memory中。内核地址空间的线性地址区间如下图所示:
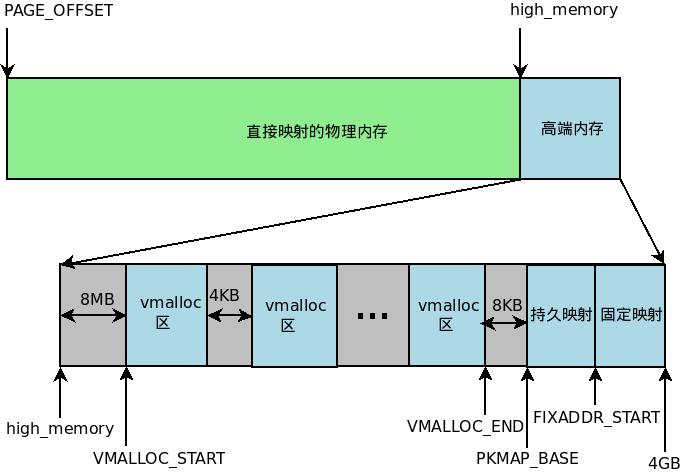
从这个图,我们可以清晰看出来从high_memory到4GB这段内存区域,系统可以使用vmalloc,也可以临时映射到用户空间的某一段内存。
总的来说高端内存映射有三种方式:
1)因为通过 vmalloc() ,在”内核动态映射空间”申请内存的时候,就可能从高端内存获得页面 (VMALLOC_START~VMALLOC_END)
2)持久映射:这个空间和其它空间使用同样的页目录表,通过内核页目录表方式达到内存映射
3)固定映射:
这块空间具有如下特点:
(1)每个 CPU 占用一块空间
(2)在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在map_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过 kmap_atomic() 可实现临时映射。