PID namespace 主要完成的功能是让不同的namespace中可以有相同的PID,子namespace与root namespace之前存在映射关系。
完成这个PID功能的主要由两个结构:
struct upid,主要表示某个特定namespace中的pid实例,而struct pid可以理解为在根root namespace中存在的pid实例,而这个实例在每个子namespace中可以有不同的upid,这个时候struct pid 下的numbers成员可以表示,在声明中我们看到numbers的大小只有1,我们可以理解为一个系统只有一个全局namespace。
如果我们创建一个子namespace,numbers的大小会动态分配,然后向namespace中添加更多的upid。
默认我们可以理解为全局namespace只有一层也就是level=0 numbers也只有1个实例。
50 struct upid {
51 /* Try to keep pid_chain in the same cacheline as nr for find_vpid */
52 int nr;
53 struct pid_namespace *ns;
54 struct hlist_node pid_chain;
55 };
56
57 struct pid
58 {
59 atomic_t count;
60 unsigned int level;
61 /* lists of tasks that use this pid */
62 struct hlist_head tasks[PIDTYPE_MAX];
63 struct rcu_head rcu;
64 struct upid numbers[1];
65 };
举例,比如我们在进行kill操作时,就会首先给进程发送一个signal,然后系统调用解析signal,最后调用到kill_something_info()的函数。http://lxr.free-electrons.com/source/kernel/signal.c#L1425。
这个函数中有一个子函数kill_pid_info(),里面的pid_task()函数就可以看到可以通过pid与pid_type查找某个特定的task_struct。从而通过控制PCB块达到控制该进程的目的。
上面我们看到系统存在以下几种类型的PID,而这个在struct pid中声明了几个散列表头的节点,用来链接每个namespace中的upid。
我们可以看到PIDTYPE_MAX为3,通过这种方式我们可以动态添加pid_type,非常方便。这里的pid_type中没有线程组TGID,但是在struct task_struct 中存在groups_leader的成员,可以利用这个成员访问pid。
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};
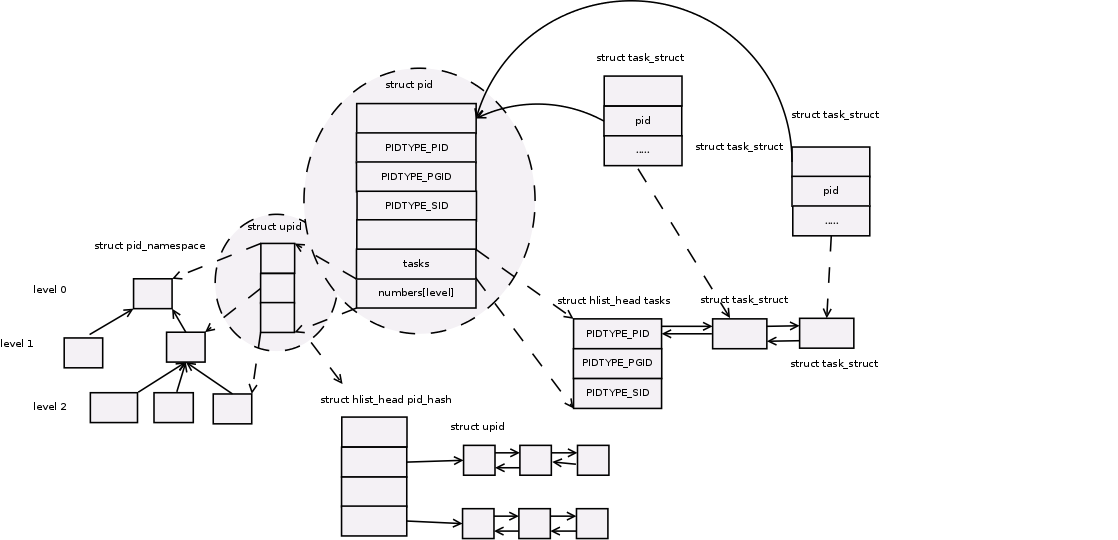
通过看这个图,我们基本可以大致的弄清楚PID namespace的结构。
系统中可以有多个struct task_struct 结构,并且他们的pid相同,指向同一个pid实例,这就表明系统中不只存在一个全局命名空间,多个struct task_struct中的pid(我们需要注意一点是在struct task_struct中pid是存在于struct pid_link pids[PDTYPE_MAX]中,还有一个pid_t pid仅仅是数值而已。通过这种方式每个struct task_struct被组织到struct hlist_head tasks的散列表数组上。)指向同一个struct pid实例,这个就要分类来看到底是何种类型的pid,通过上面的枚举,可以看到可以存在PID、PGID、SID。
内核只关心全局的pid,因为该pid肯定是唯一的,子namespace的pid查看,只需查找相关映射即可。
上面说到的通过pid可以查找task_struct,原理就是查找查找struct pid中task散列表数组,然后通过对应特定类型的type,查找该散列表上面的特定元素。具体查看http://lxr.free-electrons.com/source/kernel/pid.c#L434
至于那个numbers的数据,存放的就是每个命名空间的实例,虽然这个数据类型是upid,但是upid内部有成员函数pid_namespace 。
pid_namespace 包括指向直接的父namespace成员。
24 struct pid_namespace {
...
30 struct task_struct *child_reaper;
31 struct kmem_cache *pid_cachep;
32 unsigned int level;
33 struct pid_namespace *parent;
...
48 };
通过这个upid,我们可以找到特定pid_namespace 。依照上图,level 0的命名空间就是全局命名空间,下面的level 1 2 都是子命名空间。这种层级的组织使得父namespace可以看到子namespace的PID,反之则不行。
具体实现:http://lxr.free-electrons.com/source/kernel/pid.c#L500
除了这种树形组织结构,这些upid实例还被组织到一个pid_hash的散列表数组中。这个变量是全局的。
static struct hlist_head *pid_hash;
575 void __init pidhash_init(void)
576 {
577 unsigned int i, pidhash_size;
578
579 pid_hash = alloc_large_system_hash("PID", sizeof(*pid_hash), 0, 18,
580 HASH_EARLY | HASH_SMALL,
581 &pidhash_shift, NULL,
582 0, 4096);
583 pidhash_size = 1U << pidhash_shift;
584
585 for (i = 0; i < pidhash_size; i++)
586 INIT_HLIST_HEAD(&pid_hash[i]);
587 }
每个upid又会被组织到这个pid_hash,这样可以加快搜索。
最后就是通过各种参数查找pid、task_struct、namespace的实例,理解了数据结构,使用系统提供的内核API则不难。
参考:
http://blog.chinaunix.net/uid-20687780-id-1587537.html
http://blog.chinaunix.net/uid-20687780-id-1587608.html
http://blog.chinaunix.net/uid-20687780-id-1587702.html