在实际构建神经网络的过程中,经常碰到一些选择的问题,现在进行总结:
- Getting more training examples: Fixes high variance
- Trying smaller sets of features: Fixes high variance
- Adding features: Fixes high bias
- Adding polynomial features: Fixes high bias
- Decreasing λ: Fixes high bias
- Increasing λ: Fixes high variance.
当遇到高差异性时(high variance),可以试图增加训练样本或者减少特征数量来解决,但是如果遇到高偏见性(high bias),那么就表明这个训练集可能特征数太少,需要增加特征。λ作为惩罚系数存在,λ越大,惩罚系数越大,越可以修正高差异性,反之修正高偏见性。对于λ的取值,一般遵循在cross-validation set中取最优来决定。
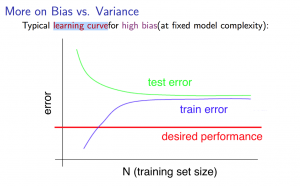
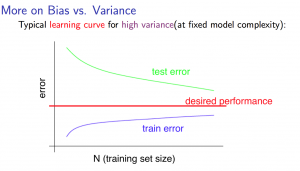
Diagnosing Neural Networks
- A neural network with fewer parameters is prone to underfitting. It is also computationally cheaper.
- A large neural network with more parameters is prone to overfitting. It is also computationally expensive. In this case you can use regularization (increase λ) to address the overfitting.
Using a single hidden layer is a good starting default. You can train your neural network on a number of hidden layers using your cross validation set. You can then select the one that performs best.只有一层的神经网络最简单,但是同时可能会造成性能损失,所以我们要增加隐藏层数和特征数,但是复杂的神经网络又会导致过拟合和计算复杂度太高的问题,所以要权衡这种平衡。
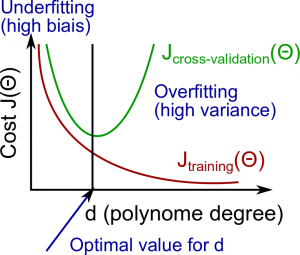
Model Complexity Effects:
- Lower-order polynomials (low model complexity) have high bias and low variance. In this case, the model fits poorly consistently.
- Higher-order polynomials (high model complexity) fit the training data extremely well and the test data extremely poorly. These have low bias on the training data, but very high variance.
- In reality, we would want to choose a model somewhere in between, that can generalize well but also fits the data reasonably well.
默认将数据集分为3部分,60%的训练集,20%的cross-validation set和20%的测试集。
参考:
https://www.coursera.org/learn/machine-learning/supplement/llc5g/deciding-what-to-do-next-revisited