之前学习过linux物理内存管理中的伙伴系统,他的分配单位是以page为单位分配。对于远远小于page的内存分配请求,比如几个字节~几百个字节,如果分配一个页框,那就是极大地浪费,会产生内部碎片,这时SLAB分配器就派上用场了。
与slab有相同地位的有slob(simple linked list of block)与slub两种备用类型的内存分配器,slob主要是使用内存块链表展开,使用最先适配算法,主要是使用在嵌入式系统,对于内存分配紧张的的系统。对于拥有大量物理内存的并行系统,slab会占用非常大的内存来存储元数据,而slub会将page打包成组,所以这里主要使用slub作为大型系统的内存分配方案。
slab、slob、slub 三者都拥有相同的内核分配函数接口。三者的选择主要在编译时就要选择确定下来。我们以slab作为下面说明的,slab会将某种特定类型的数据集中分配在一起,并且将这些对象放到高速缓存中,方便存取。
举例:进程描述符,当新进程创建时,内核直接从slab中获取一个初始化好的对象,当释放后,这个page不会放到伙伴系统,而是放入slab中。
slab分配器在最上层拥有节点是struct kmem_cache,他是slab分配器的核心结构体
struct kmem_cache {
struct array_cache __percpu *cpu_cache;
/* 1) Cache tunables. Protected by slab_mutex */
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int size;
struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */
unsigned int num; /* # of objs per slab */
/* 3) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
gfp_t allocflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *freelist_cache;
unsigned int freelist_size;
/* constructor func */
void (*ctor)(void *obj);
/* 4) cache creation/removal */
const char *name;
struct list_head list;
int refcount;
int object_size;
int align;
/* 5) statistics */
#ifdef CONFIG_DEBUG_SLAB
.....
#endif /* CONFIG_DEBUG_SLAB */
#ifdef CONFIG_MEMCG_KMEM
struct memcg_cache_params *memcg_params;
#endif
struct kmem_cache_node *node[MAX_NUMNODES];
};
这里至于管理slab的节点的数据结构就是struct kmem_cache_node,每个kmem_cache结构中并不包含对具体slab的描述,而是通过kmem_cache_node结构组织各个slab。该结构的定义如下:
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLAB
struct list_head slabs_partial; /* partial list first, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
...
};
可以看到,该结构将当前缓存中的所有slab分为三个部分:空闲对象的slab链表slabs_free,非空闲对象的slab链表slabs_full以及部分空闲对象的slab链表slabs_partial。至于在链上的结构体,在kernel 3.11前后发生了重大变化,在3.11前的版本。使用struct slab来管理slab资源。
struct slab {
union {
struct {
struct list_head list;
unsigned long colouroff;
void *s_mem; /* including colour offset */
unsigned int inuse; /* num of objs active in slab */
kmem_bufctl_t free;
unsigned short nodeid;
};
struct slab_rcu __slab_cover_slab_rcu;
};
}
在3.11之后Joonsoo Kim 提出方案认为大量的slab对象严重占用内存,所以之后struct slab融合进struct page结构体。显著降低了元数据的内存使用量,具体查看 。他并对修改后的struct page 进行了介绍 。
也就是slabs_partial 链接的是一个个struct page结构体。根据这几个结构体的关系,我们可以总结出slab的结构
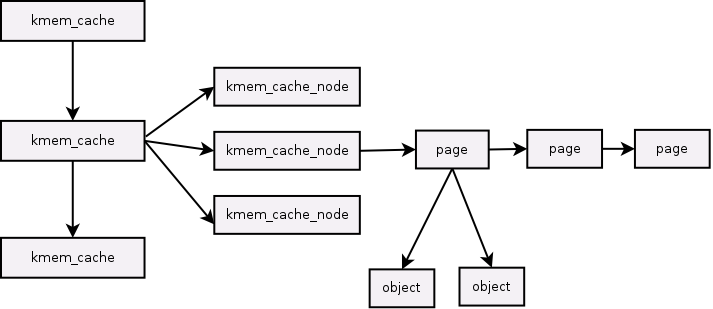
在kernel 3.11 以前,结构图是:
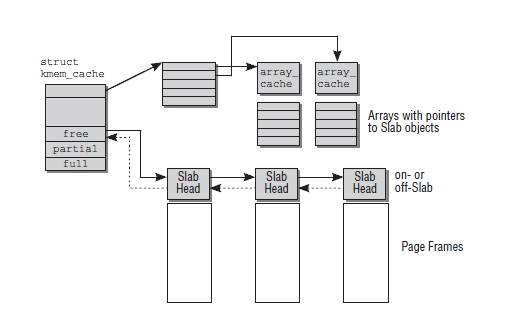
最后还要说明struct array_cache 也是一个重要的结构体,cpu首先分配一项专有object是通过struct array_cache来进行分配,这个结构体是每个cpu都会存在一个。
struct array_cache {
unsigned int avail;/*本地高速缓存中可用的空闲对象数*/
unsigned int limit;/*空闲对象的上限*/
unsigned int batchcount;/*一次转入和转出的对象数量*/
unsigned int touched; /*标识本地CPU最近是否被使用*/
spinlock_t lock;
void *entry[]; /*这是一个伪数组,便于对后面用于跟踪空闲对象的指针数组的访问
* Must have this definition in here for the proper
* alignment of array_cache. Also simplifies accessing
* the entries.
*/
};
在每个array_cache的末端都用一个指针数组记录了slab中的空闲对象,分配对象时,采用LIFO方式,也就是将该数组中的最后一个索引对应的对象分配出去,以保证该对象还驻留在高速缓存中的可能性。实际上,每次分配内存都是直接与本地CPU高速缓存进行交互,只有当其空闲内存不足时,才会从kmem_list中的slab中引入一部分对象到本地高速缓存中,而kmem_list中的空闲对象也不足了,那么就要从伙伴系统中引入新的页来建立新的slab了,这一点也和伙伴系统的每CPU页框高速缓存很类似。
slab高速缓存分为两类,普通高速缓存和专用高速缓存。
- 普通高速缓存并不针对内核中特定的对象,它首先会为kmem_cache结构本身提供高速缓存,这类缓存保存在cache_cache变量中,该变量即代表的是cache_chain链表中的第一个元素;
- 专用高速缓存为内核提供了一种通用高速缓存。专用高速缓存是根据内核所需,通过指定具体的对象而创建。
最后使用这种slab分配非常简单
1.创建
struct kmem_cache *cachep = NULL;
cachep = kmem_cache_create("cache_name", sizeof(struct yourstruct), 0, SLAB_HWCACHE_ALIGN, NULL, NULL);
2.分配一个struct yourstruct的结构体空间时
调用kmem_cache_alloc函数,就可以获得一个足够使用的空间的指针(SLAB_HWCACHE_ALIGN,这个标志会让分配的空间对于硬件来说是对齐的,而不一定恰好等于sizeof(struct yourstruct)的结果)。范例代码如下:
struct yourstruct *bodyp = NULL; bodyp = (struct yourstruct *) kmem_cache_alloc(cachep, GFP_ATOMIC & ~__GFP_DMA);
3.销毁
kmem_cache_free(cachep, bodyp);
参考:
http://lwn.net/Articles/570504/
https://lwn.net/Articles/565097/
https://lwn.net/Articles/335768/
http://blog.csdn.net/vanbreaker/article/details/7664296