这里有一个大文本(一些经典英文小说的集合),文件在解压后大约有20m。
文本中都是英文单词,空格以及英文的标点符号: [.,;-~”?’!] (句号,逗号,分号,破折号,波浪号,双引号,问号,单引号,感叹号)
任务要求:请统计出该文本中最常出现的前10个单词(不区分大小写)。
请注意,在统计中这20个单词请忽略(the, and, i, to, of, a, in, was, that, had, he, you, his, my, it, as, with, her, for, on)
说明:
1) 编程语言不限
2) 最终的测试机器为多核环境(单机)
3) 不得借助外部服务 (调用远程服务)
4) 可引用外部框架或库(限开源)
先放入map容器,然后计数。将他套入 vector< pair< string,int> > tVector; 中,然后重写cmp函数,使用sort(tVector.begin(), tVector.end(), cmp)排序。
version 1.0
//输入单词,统计单词出现次数并按照单词出现次数从多到少排序
#include
#include
<map>
#include
#include
#include
#include
#include
#include
using namespace std;
void sortMapByValue(map<std::string, int>& tMap, vector<std::pair<std::string, int> >& tVector);
int cmp(const pair<string, int>& x, const pair<string, int>& y);
void toLowerCase(string& str);
int main()
{
string word,temp;
fstream myfile;
myfile.open("./document.txt",ios::in);
map<std::string, int> tMap;
pair< map< string, int>::iterator, bool> ret;
clock_t start,finish;
start=clock();
if (myfile.is_open())
{
while (myfile >> word)
{
toLowerCase(word);
if(word == "at" || word == "me"|| word == "him" || word == "she"|| word == "the" || word == "The"|| word =="and" || word == "I" || word == "i"|| word =="to" || word=="of" || word =="a" ||word=="in"
||word =="was" ||word =="that" ||word =="had" || word =="he" || word =="you"
|| word=="his" || word =="my" ||word=="it" ||word =="as" || word =="with" ||
word =="her" || word =="for" || word=="on" )
{
continue;
}
if(word[word.length()-2]=='\'' )
{
temp = temp.assign(word,0,word.length()-3);
ret = tMap.insert( make_pair(temp, 1));
}
else if( (word[word.length()-1]>'A' && word[word.length()-1] <'Z' )|| (word[word.length()-1]>'a' && word[word.length()-1]<'z')) { ret = tMap.insert( make_pair(word, 1)); } else { temp = temp.assign(word,0,word.length()-1); ret = tMap.insert( make_pair(temp, 1)); } if (!ret.second) ++ret.first->second;
}
myfile.close();
}
else
{
cout<< "Open fail!"<<endl;
return 0;
}
vector< pair< string,int> > tVector;
sortMapByValue(tMap,tVector);
finish=clock();
cout<<" Clock: "<< (finish-start)/CLOCKS_PER_SEC<<endl;
for(int i=0;i<10;i++)//前10个, tVector.size()
{
cout<<tVector[i].first<<": "<<tVector[i].second<< endl;
}
system("pause");
return 0;
}
int cmp(const pair<string, int>& x, const pair<string, int>& y)
{
return x.second > y.second;
}
void sortMapByValue(map<string, int>& tMap, vector<pair<string, int> >& tVector)
{
for (map<string, int>::iterator curr = tMap.begin(); curr != tMap.end(); curr++)
{
tVector.push_back(make_pair(curr->first, curr->second));
}
sort(tVector.begin(), tVector.end(), cmp);
}
void toLowerCase(string& str)
{
for (int i = 0; i < str.length(); ++i) if (str[i] >= 'A' && str[i] <= 'Z')
str[i] += ('a' - 'A');
}
version 2.0
第一版的程序缺点就是耗时长,根本原因在于map使用红黑树写的,查找插入删除的时间复杂度是log(n)。
第二版的程序我是用了hash_map(),查找修改的时间复杂度是o(1) ,插入是log(n)。
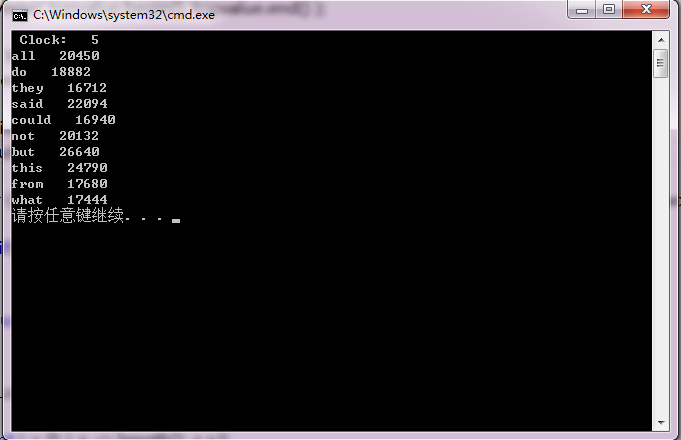
#include
#include
#include
#include <hash_map>
#include
#include
using namespace std;
using namespace stdext;
typedef pair<std::string, int> Int_Pair;
void toLowerCase(string& str);
int main()
{
string temp;
string word;
stdext::hash_map <std::string, int> words;
stdext::hash_map <std::string, int>::iterator wordsit;
ifstream myfile("./document.txt");
clock_t start,finish;
start=clock();
if (myfile.is_open())
{
while ( myfile >> word )
{
toLowerCase(word);
if(word == "at" || word == "me"|| word == "him" || word == "she"|| word == "the" || word == "The"|| word =="and" || word == "I" || word == "i"|| word =="to" || word=="of" || word =="a" ||word=="in"
||word =="was" ||word =="that" ||word =="had" || word =="he" || word =="you"
|| word=="his" || word =="my" ||word=="it" ||word =="as" || word =="with" ||
word =="her" || word =="for" || word=="on" )
{
continue;
}
if(word[word.length()-2]=='\'' )
{
temp = temp.assign(word,0,word.length()-3);
}
else if( (word[word.length()-1]>'A' && word[word.length()-1] <'Z' )|| (word[word.length()-1]>'a' && word[word.length()-1]<'z'))
{
temp = temp.assign(word,0,word.length());
}
else
{
temp = temp.assign(word,0,word.length()-1);
}
//cout << temp <<endl; wordsit = words.find(temp); if (wordsit != words.end()) ++(wordsit->second);
else
{
words.insert( Int_Pair(temp,1) );
}
}
myfile.close();
}
else
{
cout<<"Open Fail ......"<<endl;
return 0;
}
std::vector < int > topvalue;
int threshold = 0;
for ( stdext::hash_map <std::string, int>::iterator wordsit = words.begin(); wordsit != words.end();wordsit++ )
{
topvalue.push_back( wordsit->second );
}
sort( topvalue.begin(), topvalue.end() );
reverse( topvalue.begin(), topvalue.end() );
if ( topvalue.size() > 10 )
threshold = topvalue[9];
finish=clock();
cout<<" Clock: "<< (finish-start)/CLOCKS_PER_SEC<<endl;
for ( stdext::hash_map <std::string, int>::iterator wordsit = words.begin(); wordsit != words.end(); wordsit++ )
{
if( wordsit->second >= threshold )
cout << wordsit->first << " " << wordsit->second<< endl;
}
return 0;
}
void toLowerCase(string& str)
{
for (int i = 0; i < str.length(); ++i) if (str[i] >= 'A' && str[i] <= 'Z')
str[i] += ('a' - 'A');
}