最近遇到一个棘手的问题,公司的海外服务器有大量的Tcp ListenDrops,经过检查服务日志,没有发现任何异常日志,然后我进行了艰苦的排查。
使用tcpdump工具进行抓包,由于公司数据比较敏感,就自己搭了一个演示环境来展示。
➜ ~ sudo tcpdump tcp -i ens33 -vv -s 0 -t and “tcp[tcpflags] & (tcp-syn) != 0”
tcpdump: listening on ens33, link-type EN10MB (Ethernet), capture size 262144 bytes
IP (tos 0x0, ttl 64, id 24397, offset 0, flags [DF], proto TCP (6), length 60)
192.168.175.128.50990 > 61.135.169.125.https: Flags [S], cksum 0x575c (incorrect -> 0x79ee), seq 4195193728, win 29200, options [mss 1460,sackOK,TS val 315071380 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 64, id 32393, offset 0, flags [DF], proto TCP (6), length 60)
192.168.175.128.50992 > 61.135.169.125.https: Flags [S], cksum 0x575c (incorrect -> 0xaa39), seq 2868687428, win 29200, options [mss 1460,sackOK,TS val 315071380 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 64, id 46350, offset 0, flags [DF], proto TCP (6), length 60)
192.168.175.128.50994 > 61.135.169.125.https: Flags [S], cksum 0x575c (incorrect -> 0x77da), seq 366705091, win 29200, options [mss 1460,sackOK,TS val 315071380 ecr 0,nop,wscale 7], length 0
IP (tos 0x0, ttl 128, id 19582, offset 0, flags [none], proto TCP (6), length 44)
61.135.169.125.https > 192.168.175.128.50990: Flags [S.], cksum 0x555f (correct), seq 2100960485, ack 4195193729, win 64240, options [mss 1460], length 0
IP (tos 0x0, ttl 128, id 19586, offset 0, flags [none], proto TCP (6), length 44)
61.135.169.125.https > 192.168.175.128.50992: Flags [S.], cksum 0x8649 (correct), seq 2037522446, ack 2868687429, win 64240, options [mss 1460], length 0
IP (tos 0x0, ttl 128, id 19587, offset 0, flags [none], proto TCP (6), length 44)
61.135.169.125.https > 192.168.175.128.50994: Flags [S.], cksum 0x4ca9 (correct), seq 1789015583, ack 366705092, win 64240, options [mss 1460], length 0
通过这个日志,我们能看出我的主机向61.135.169.125发送 SYN 和 61.135.169.125向我回包的过程,能看出满足三次握手的过程,里面的Flags就是TCP标志位,S 是 SYN,. 就是ack。根据TCP包头:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data | |C|E|U|A|P|R|S|F| |
| Offset| Res. |W|C|R|C|S|S|Y|I| Window |
| | |R|E|G|K|H|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
上面的那个Options就是我们重点关注的。
一般丢包会从以下几个方面考虑:
防火墙拦截
服务器端口无法连接,通常就是查看防火墙配置了,虽然这里已经确认同一个出口IP的客户端有的能够正常访问,但也不排除配置了DROP特定端口范围的可能性。
连接跟踪表溢出
除了防火墙本身配置DROP规则外,与防火墙有关的还有连接跟踪表nf_conntrack,Linux为每个经过内核网络栈的数据包,生成一个新的连接记录项,当服务器处理的连接过多时,连接跟踪表被打满,服务器会丢弃新建连接的数据包。dmesg |grep nf_conntrack
Ring Buffer溢出
通过ethtool或/proc/net/dev可以查看因Ring Buffer满而丢弃的包统计,在统计项中以fifo标识:
➜ ~ ethtool -S ens33 | grep tx_fifo_errors
tx_fifo_errors: 0
如果发现服务器上某个网卡的fifo数持续增大,可以去确认CPU中断是否分配均匀,也可以尝试增加Ring Buffer的大小,通过ethtool可以查看网卡设备Ring Buffer最大值,修改Ring Buffer当前设置: ethtool -G eth0 rx 4096 tx 4096
netdev_max_backlog溢出
netdev_max_backlog是内核从NIC收到包后,交由协议栈(如IP、TCP)处理之前的缓冲队列。每个CPU核都有一个backlog队列,与Ring Buffer同理,当接收包的速率大于内核协议栈处理的速率时,CPU的backlog队列不断增长,当达到设定的netdev_max_backlog值时,数据包将被丢弃。
半连接队列溢出
半连接队列指的是TCP传输中服务器收到SYN包但还未完成三次握手的连接队列,队列大小由内核参数tcp_max_syn_backlog定义。
PAWS
PAWS全名Protect Againest Wrapped Sequence numbers,目的是解决在高带宽下,TCP序列号在一次会话中可能被重复使用而带来的问题。
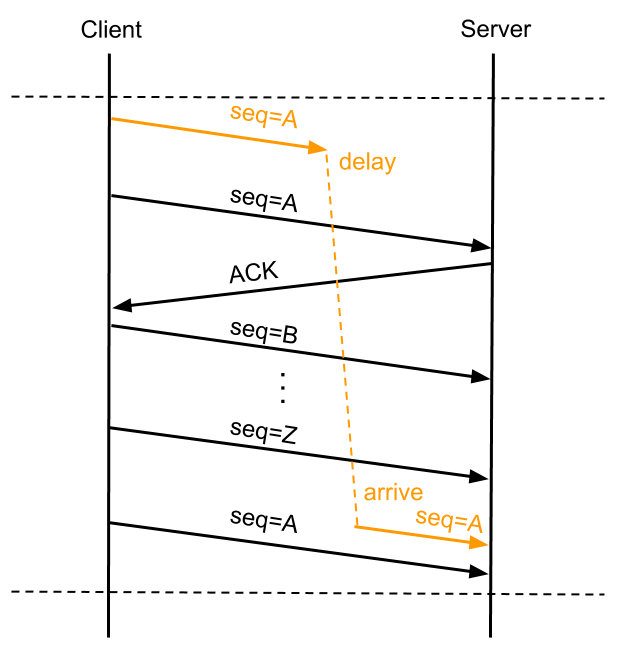
如上图所示,客户端发送的序列号为A的数据包A1因某些原因在网络中“迷路”,在一定时间没有到达服务端,客户端超时重传序列号为A的数据包A2,接下来假设带宽足够,传输用尽序列号空间,重新使用A,此时服务端等待的是序列号为A的数据包A3,而恰巧此时前面“迷路”的A1到达服务端,如果服务端仅靠序列号A就判断数据包合法,就会将错误的数据传递到用户态程序,造成程序异常。
PAWS要解决的就是上述问题,它依赖于timestamp机制,理论依据是:在一条正常的TCP流中,按序接收到的所有TCP数据包中的timestamp都应该是单调非递减的,这样就能判断那些timestamp小于当前TCP流已处理的最大timestamp值的报文是延迟到达的重复报文,可以予以丢弃。在上文的例子中,服务器已经处理数据包Z,而后到来的A1包的timestamp必然小于Z包的timestamp,因此服务端会丢弃迟到的A1包,等待正确的报文到来。
PAWS机制的实现关键是内核保存了Per-Connection的最近接收时间戳,如果加以改进,就可以用来优化服务器TIME_WAIT状态的快速回收。
TIME_WAIT状态是TCP四次挥手中主动关闭连接的一方需要进入的最后一个状态,并且通常需要在该状态保持2*MSL(报文最大生存时间),它存在的意义有两个:
1.可靠地实现TCP全双工连接的关闭:关闭连接的四次挥手过程中,最终的ACK由主动关闭连接的一方(称为A)发出,如果这个ACK丢失,对端(称为B)将重发FIN,如果A不维持连接的TIME_WAIT状态,而是直接进入CLOSED,则无法重传ACK,B端的连接因此不能及时可靠释放。
2.等待“迷路”的重复数据包在网络中因生存时间到期消失:通信双方A与B,A的数据包因“迷路”没有及时到达B,A会重发数据包,当A与B完成传输并断开连接后,如果A不维持TIME_WAIT状态2*MSL时间,便有可能与B再次建立相同源端口和目的端口的“新连接”,而前一次连接中“迷路”的报文有可能在这时到达,并被B接收处理,造成异常,维持2*MSL的目的就是等待前一次连接的数据包在网络中消失。
TIME_WAIT状态的连接需要占用服务器内存资源维持,Linux内核提供了一个参数来控制TIME_WAIT状态的快速回收:tcp_tw_recycle,它的理论依据是:
在PAWS的理论基础上,如果内核保存Per-Host的最近接收时间戳,接收数据包时进行时间戳比对,就能避免TIME_WAIT意图解决的第二个问题:前一个连接的数据包在新连接中被当做有效数据包处理的情况。这样就没有必要维持TIME_WAIT状态2*MSL的时间来等待数据包消失,仅需要等待足够的RTO(超时重传),解决ACK丢失需要重传的情况,来达到快速回收TIME_WAIT状态连接的目的。
如何确认
通过netstat可以得到因PAWS机制timestamp验证被丢弃的数据包统计:
$ netstat –s |grep –e “passive connections rejected because of time stamp” –e “packets rejects in established connections because of timestamp”
387158 passive connections rejected because of time stamp
825313 packets rejects in established connections because of timestamp
通过sysctl查看是否启用了tcp_tw_recycle及tcp_timestamp:
$ sysctl net.ipv4.tcp_tw_recycle
net.ipv4.tcp_tw_recycle = 1
$ sysctl net.ipv4.tcp_timestamps
net.ipv4.tcp_timestamps = 1
这次问题正是因为服务器同时开启了tcp_tw_recycle和timestamps,而客户端正是使用NAT来访问服务器,造成启动时间相对较短的客户端得不到服务器的正常响应。
如何解决
如果服务器作为服务端提供服务,且明确客户端会通过NAT网络访问,或服务器之前有7层转发设备会替换客户端源IP时,是不应该开启tcp_tw_recycle的,而timestamps除了支持tcp_tw_recycle外还被其他机制依赖,推荐继续开启:
Linux提供了丰富的内核参数供使用者调整,调整得当可以大幅提高服务器的处理能力,但如果调整不当,就会引进莫名其妙的各种问题,比如这次开启tcp_tw_recycle导致丢包,实际也是为了减少TIME_WAIT连接数量而进行参数调优的结果。我们在做系统优化时,时刻要保持辩证和空杯的心态,不盲目吸收他人的果,而多去追求因,只有知其所以然,才能结合实际业务特点,得出最合理的优化配置。
上面这些都是网卡层面的丢包,而我遇到的情况是tcp丢包,网卡并没有什么异常,最后通过tcpdump抓包,发现有大量的SYN,没有ack回包,究其原因就是tcp_tw_recycle导致的,其中针对这个time stamp就是放在TCP包头的Options 参数里,通过tcpdump也是可以看到这个参数的(TS val 315071380),默认我们的服务器经过LB打过来后,经过NAT访问服务器时会产生新的问题:同一个NAT背后的多个客户端时间戳是很难保持一致的(timestamp机制使用的是系统启动相对时间),对于服务器来说,两台客户端主机各自建立的TCP连接表现为同一个对端IP的两个连接,按照Per-Host记录的最近接收时间戳会更新为两台客户端主机中时间戳较大的那个,而时间戳相对较小的客户端发出的所有数据包对服务器来说都是这台主机已过期的重复数据,因此会直接丢弃,因此产生tcp listen drop。
参考